OCR scanning transforms images of handwritten or printed text into digital data that can be easily searched and manipulated, making it simple to store documents. The development of this process began more than one hundred years ago, and it has evolved to the present, where AI-based systems process numerous written formats alongside different handwriting styles and document formats.
Current OCR technology systems integrate seamlessly with digital workflow systems, encompassing solutions ranging from basic mobile translation of street signs to complex automated invoice handling in enterprise-level operations. The reliable PDF Agile software is a comprehensive PDF editor with integrated high-accuracy OCR functions, ensuring smart document searchability.
This article examines the origins of OCR, discussing its inner mechanics, typical versions, and practical applications, while also explaining the obstacles that remain in determining what constitutes top-notch OCR software. So, what is OCR scanning?

A Peek into History: The Evolution of OCR
The history of OCR technology dates back to the early 1900s. In 1914, Emanuel Goldberg constructed a machine that converted printed characters into telegraph code. In the 1950s, IBM employees developed OCR devices under David Shepard, who operated specific typeface recognition tools that utilized early computer processing methods.
Though cumbersome and limited in operation, OCR created the fundamental principles for controlling digital text processing. Recently developed technologies have transformed OCR from a specialized tool into a comprehensive commercial solution, following several decades of advancements in computing power, image sensors, and algorithmic development.
Most offices received their inaugural experience with desktop OCR when PC scanners became available during the 1990s. Machine learning algorithms in contemporary systems enable them to process numerous fonts, different handwriting styles, and intricate document formats without requiring manual training of individual fonts or color formats.

How It Works: From Scan to Text?
Here’s the typical OCR workflow:
- Image Acquisition: You start with a scanned document or a photo. This raw image is the canvas for OCR software.
- Pre-processing: The program enhances image quality by performing a series of processes, which include directing the image shape through de-skewing while boosting contrast through binarization and despeckling, which clears text.
- Layout Analysis: The software identifies the positions of text blocks, together with images and tables, to understand which areas it should extract information from.
- Character Recognition: Two main approaches take over: 1. Pattern Matching: Compares shapes against templates of known characters. 2. Feature Extraction: Breaks down strokes, loops, and edges to identify letters based on distinctive traits.
- Post-processing: The software stitches recognized characters into text, applies dictionaries or context rules to catch errors, and outputs a searchable PDF or document.
Types of OCR Technologies
1. Traditional OCR: Traditional OCR focuses on printed text in clean, standard fonts. The algorithm performs well for the quick and consistent recognition of documents containing clear text with a single typeface, but it fails when dealing with random page arrangements.
2. Intelligent Character Recognition (ICR): Handwriting recognition technology, also known as Intelligent Character Recognition (ICR), operates within handwritten text. ICR operates through neural networks that can handle diverse writing but yield inconsistent accuracy results.
3. Optical Word Recognition (OWR): The optical word recognition technology skips individual letters to analyze whole words by guessing language context, which works best for complex writing systems or cases of lower letter accuracy.
4. AI-Powered OCR: AI-powered OCR leverages deep learning to understand document structure, translate languages, and extract data tables with minimal human intervention.
OCR in Real-World Applications
You probably bump into OCR every day without realizing it:
1. Business Automation: The process of scanning invoices, receipts, business cards, and contracts through databases and CRM systems leads to an automatic data population, reducing extensive manual labor to brief periods.
2. Banking & Finance: Processing checks, loan forms, and statements automatically, boosting speed and reducing fraud risks by instantly validating document data.
3. Healthcare: The electronic transformation of patients' healthcare information enables doctors to perform archival searching and share records without requiring the retrieval of paper documents.
4. Retail & Loyalty Programs: Clients can redeem benefits through cashback points by taking pictures of their receipts, which utilize optical character recognition (OCR) technology to scan store information, including dates and expense totals.
5. Government & Archives: Preserving historical documents and public records by converting fragile paper files into searchable digital archives, ensuring nothing gets lost to time.
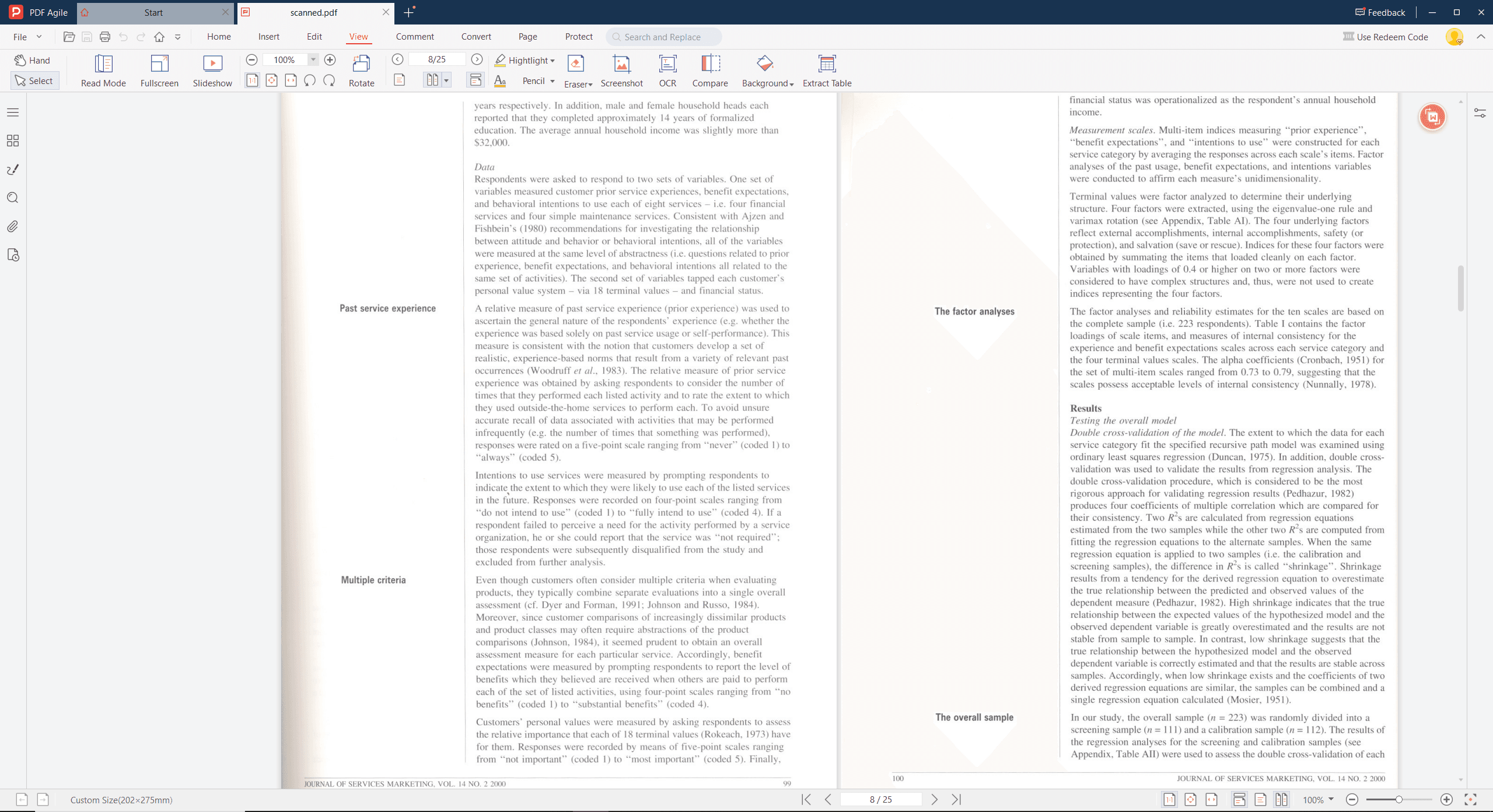
The Tough Bits: Limitations and Challenges
OCR isn’t magic. Its accuracy still hinges on:
Image Quality: Character detection systems struggle significantly when images are blurred, have inadequate lighting, or are of low resolution.
Fonts & Handwriting: All forms of non-standard writing styles, such as different fonts and cursive handwriting, as well as those written in a disorganized manner, pose challenges even for the most advanced recognition systems today.
Complex Layouts: The identification process of zoning algorithms is disrupted when pages use multiple columns or contain tables within text, or when images are placed within the text.
Context Understanding: The process of OCR generates word recognition without complete meaning interpretation, which could lead to homonyms or context-dependent terms remaining unproofed.
Peeking Ahead: Future Trends
The next evolution of OCR merges AI technology with enhanced accessibility to improve its capabilities:
- Cloud-Based OCR Services: Cloud-based OCR Services connect you to fast-computing servers that operate without local hardware complications.
- Mobile SDKs: Mobile SDKs embed OCR functionality within travel, translation, and field-service applications to perform real-time detection of multiple languages in images, texts, and documents.
- Hybrid AI Models: Hybrid AI Models unite OCR technology with natural language processing to retrieve textual content and document meaning, along with sentiment analysis and intended objectives, generating summaries automatically.
Why PDF Agile?
PDF Agile provides comprehensive scanning, editing, and OCR solutions. It boasts:
- Advanced recognition engines deliver accurate performance through high accuracy.
- Users can achieve simplified document processes by utilizing built-in scanner features, along with OCR capabilities and text editor functions, all of which operate through a single-click sequence.
- Users can generate searchable PDFs, Word files, and text snippets as saved outputs.
- The system offers affordable licenses that cater to a wide range of users, including small businesses and individual customers.
All the above make PDF Agile a smart pick when you ask what OCR is or what OCR scanning is for your day-to-day PDF needs.
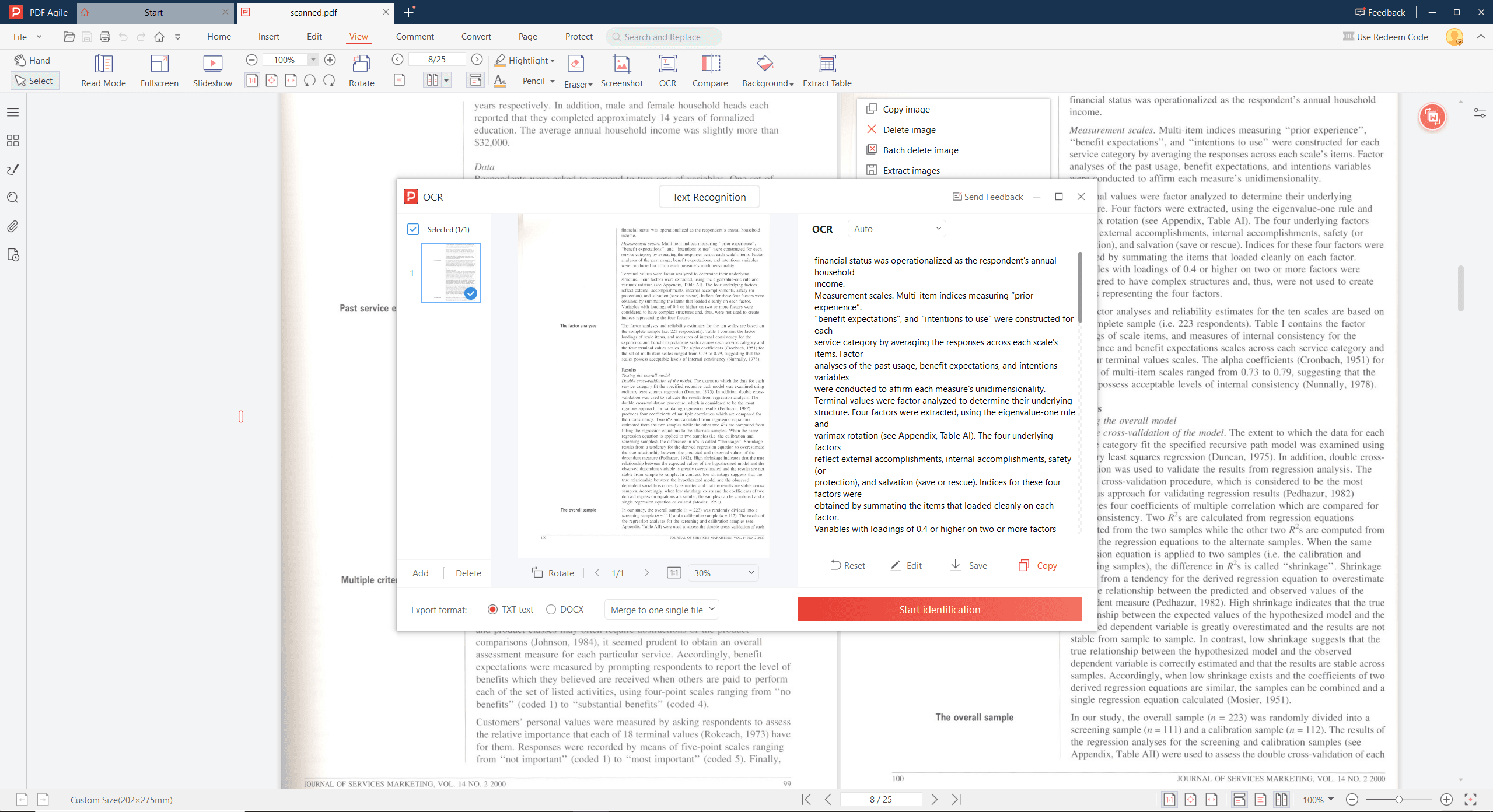
FAQs
Q: How accurate is OCR?
A: The accuracy in these top tools depends on image clarity, as well as document complexity; however, they achieve accuracy rates of greater than 98% for clear printed text.
Q: Can OCR read handwriting?
A: ICR technology recognizes clear handwriting but achieves varying success points with a precision range between 80–90 percent for good handwriting versus lower precision for unclear handwriting.
Q: What file formats work best for OCR?
A: High-resolution JPEG, TIFF, and PDF files are ideal for this purpose. Avoid low-res or compressed images that blur text.
Q: How do I improve OCR results?
A: Use clean originals, scan 300+ DPI, straighten pages, and crop out extraneous borders before processing.
Conclusion
The discussion has explored everything about what OCR is and what OCR scanning is, through its historical background and modern technology for image text recognition. This article on OCR has revealed various types of recognition, along with their business applications, and ongoing hurdles that drive technological advancements. OCR technology is currently integrating AI and NLP, and its capability to extract both text and meaning from documents will continue to improve. This will transform our approaches to handling information. Finally, you can find more interesting knowledge articles in Knowledge | PDF Agile.