






























Risques cachés pour la sécurité des PDF dans le traitement par IA
Comment les modèles d'IA cloud publics peuvent compromettre la sécurité des PDF
Les outils d'IA générative tels que ChatGPT, Copilot, Gemini et autres services de PDF AI font désormais partie intégrante de l'espace de travail numérique moderne. Les équipes collent régulièrement des extraits de code, des propositions confidentielles ou des données clients dans ces modèles et les utilisent pour la synthèse, la traduction ou la conversion. Cependant, de nombreux services d'IA publics déclarent ouvertement qu'ils conservent les requêtes des utilisateurs indéfiniment à des fins d'entraînement. Une fois que votre PDF a été absorbé dans les données d'entraînement d'un modèle d'IA, il fait partie de la base de connaissances du modèle ; sa récupération ou sa suppression est difficile et souvent impossible. Le rapport UpGuard « Shadow AI Data Leak » explique que les employés supposent souvent que ces outils sont privés et sécurisés, mais la réalité est tout autre. Les politiques de conservation des données sont vagues, et les modèles peuvent stocker vos PDF sensibles et les utiliser pour améliorer leurs algorithmes sans aucune garantie d'anonymisation.
Fuites cachées par mémorisation des modèles
Les modèles d'IA ne se contentent pas de généraliser ; ils mémorisent également. Selon le guide de sécurité des données d'entraînement de Cloudflare, une « fuite par mémorisation » se produit lorsque les sorties d'un modèle reproduisent des parties de ses données d'entraînement. Une telle fuite peut survenir à plusieurs niveaux : pendant l'entraînement lorsque des données sensibles intègrent l'ensemble de données, lors de l'inférence lorsque des attaquants élaborent des requêtes pour amener un modèle à révéler des données internes, ou même via le partage de gradients lors de l'entraînement distribué. L'analyse de GitGuardian sur GitHub Copilot a montré que le modèle pouvait reproduire des secrets appris à partir de dépôts de code publics. Lorsque le PDF confidentiel de votre organisation est téléchargé vers un modèle d'IA cloud — même un modèle « anonyme » — il existe un risque que le modèle régurgite involontairement des parties de votre document en réponse à la requête d'un tiers. L'anonymisation ne résout pas ce problème car des fragments de code ou de texte peuvent être agrégés et ré-identifiés.
Exemples réels de violations de sécurité PDF dans les flux de travail IA
```htmlEn mars 2023, des ingénieurs de la division semi-conducteurs de Samsung ont collé du code source propriétaire et des notes de réunion confidentielles dans ChatGPT pour déboguer des problèmes et résumer des rapports internes. Les informations saisies dans ChatGPT ont été intégrées dans la base de données du modèle, ce qui a poussé Samsung à publier une note de service interdisant les outils d'IA générative et à interroger son personnel sur les préoccupations de sécurité. Soixante-cinq pour cent des répondants se sont déclarés inquiets des risques de sécurité. Des incidents similaires chez Amazon et d'autres institutions financières ont conduit à des restrictions strictes sur l'utilisation de l'IA générative. Ces cas illustrent à quel point il est facile pour les secrets commerciaux contenus dans des PDF de fuir lorsque les employés utilisent des outils d'IA publics sans mesures de protection.
Risques Réglementaires : Quand la Sécurité des Données PDF Échappe à Tout Contrôle
Au-delà de l'atteinte à la réputation et de la perte d'avantage concurrentiel, les fuites de données liées à l'IA peuvent entraîner des amendes réglementaires. Le Règlement Général sur la Protection des Données (RGPD) impose des obligations strictes aux organisations qui traitent des données personnelles. L'article 25 exige une « protection des données dès la conception et par défaut », ce qui signifie que les responsables du traitement doivent mettre en œuvre des mesures techniques et organisationnelles pour garantir que, par défaut, seules les données personnelles nécessaires à chaque finalité spécifique soient traitées. Il précise en outre que les données personnelles ne doivent pas être rendues accessibles à un nombre indéfini de personnes. Le California Consumer Privacy Act (CCPA) donne aux consommateurs le droit de savoir quelles informations personnelles sont collectées, le droit de les supprimer, le droit de refuser leur vente ou leur partage et la protection contre la discrimination pour l'exercice de ces droits. Lorsque les données d'un PDF sont transmises à un modèle d'IA externe, l'organisation peut être dans l'incapacité d'honorer les demandes de suppression ou de refus, l'exposant ainsi à une responsabilité juridique. Par conséquent, atteindre la conformité exige plus qu'une politique de confidentialité — cela nécessite de concevoir des flux de travail d'IA qui n'envoient jamais de données sensibles vers un modèle cloud non contrôlé.
Comment Protéger les Fichiers PDF avec une IA Locale (Zéro Téléchargement de Données)
Comprendre le Traitement Local
``````htmlLe logiciel « local‑first » est un modèle architectural dans lequel tout le traitement et le stockage se déroulent par défaut sur l’appareil de l’utilisateur. Des opérations telles que l’édition, l’OCR et la conversion sont exécutées en mémoire, et seul l’utilisateur peut déclencher la synchronisation ou le partage. Un éditeur PDF local‑first sur GitHub, Simple VaultPDF, met en évidence les principes clés de ce modèle : tout le traitement s’effectue localement, sans dépendance au cloud. Ses fonctionnalités incluent l’édition, le réordonnancement, la fusion, la division et l’OCR, le tout exécuté hors ligne. Le dépôt insiste sur une conception privée par défaut, précisant que les fichiers ne quittent jamais l’appareil et qu’aucune donnée n’est collectée ni transmise. De même, le projet PDF Editor Offline souligne que les documents restent sur l’appareil de l’utilisateur, qu’aucun compte n’est requis et qu’il n’y a aucun téléchargement forcé vers le cloud. Il s’appuie sur un backend FastAPI + PyMuPDF et un frontend React + TypeScript pour traiter les PDF au sein d’une session locale.
Bonnes pratiques pour la sécurité des PDF dans les workflows d’IA
L’intégration de fonctionnalités d’IA dans un éditeur PDF — comme le résumé, la traduction ou la conversion — repose souvent sur des modèles d’apprentissage automatique. De nombreux fournisseurs envoient les PDF vers des serveurs distants pour analyse, mais un créateur de PDF IA local‑first peut exécuter ces modèles localement grâce à WebAssembly ou à l’accélération matérielle. Puisque les modèles s’exécutent en mémoire, le contenu sensible n’est jamais transmis ; cela satisfait par conception aux exigences de minimisation des données du RGPD et de droit de refus du CCPA. L’architecture local‑first réduit également la latence, évite les pannes réseau et élimine la dépendance vis-à-vis des fournisseurs de services tiers. Par exemple, les fonctionnalités de Simple VaultPDF incluent l’OCR via Tesseract.js et la capacité de convertir des pages PDF en images ou en texte de haute qualité — le tout sans communication réseau. Dans le projet PDF Editor Offline, les fonctions de conversion permettent d’exporter des PDF vers Word, PowerPoint, Excel ou des images et d’importer divers formats vers les PDF. En intégrant un Créateur de PDF IA ou un Convertisseur IA PDF vers Word dans un tel cadre local‑first, les développeurs peuvent offrir de puissantes capacités d’IA tout en garantissant que les documents et leurs embeddings dérivés ne quittent jamais la machine.
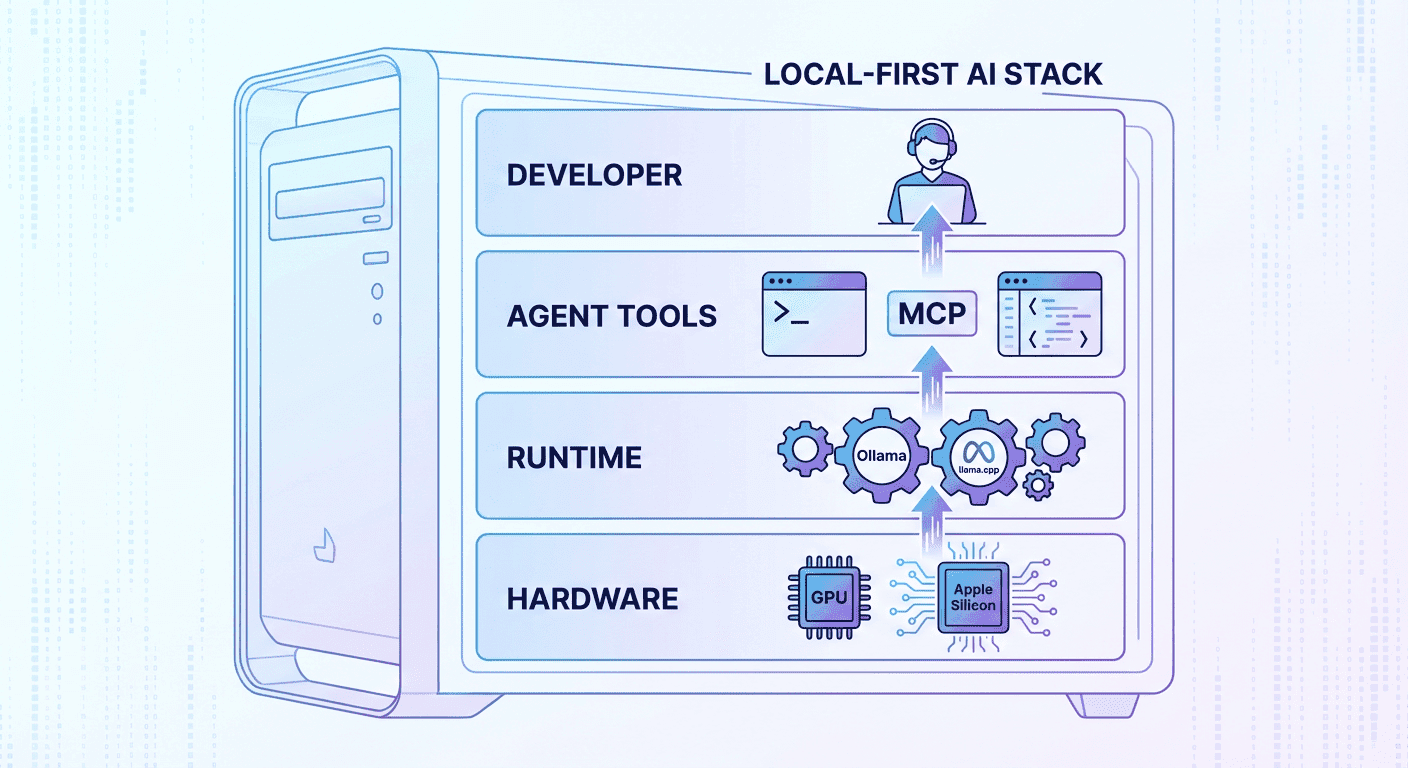
Comment obtenir une empreinte cloud de zéro octet
Pour atteindre « zéro octet téléversé », un système PDF IA local‑first doit respecter plusieurs principes de conception fondamentaux :
Traitement dans le navigateur : Utiliser WebAssembly ou des bibliothèques natives compilées pour s'exécuter dans le navigateur, afin que les algorithmes opèrent dans l'environnement du client. Les projets GitHub que nous avons cités implémentent l'OCR et la manipulation de PDF à l'aide de Tesseract.js et PyMuPDF.
Aucun appel API externe par défaut : L'application ne doit pas solliciter de points de terminaison externes pour effectuer des tâches IA ou des analyses. Tous les journaux et traitements se déroulent localement, en conformité avec l'exigence de l'article 25 du RGPD de limiter la quantité et l'accessibilité des données personnelles.
Synchronisation optionnelle via chiffrement : Lorsqu'une synchronisation ou une sauvegarde dans le cloud est nécessaire, le système doit chiffrer les fichiers sur le client avant le transfert et n'envoyer que des octets chiffrés. Les clés restent sous le contrôle de l'utilisateur. Sans la clé, le fournisseur cloud ne peut pas accéder au contenu des documents, satisfaisant ainsi le droit à la suppression et le droit de refus du CCPA.
Transparence open‑source : Le code open‑source permet aux organisations d'auditer l'implémentation et de vérifier qu'aucun appel réseau caché ni télémétrie n'existe. Simple VaultPDF et PDF Editor Offline sont publiés sous licences permissives et mettent l'accent sur la transparence.
Ensemble, ces principes garantissent qu'aucun octet de votre PDF ne quitte l'environnement local, sauf si vous décidez explicitement de le partager.
Conformité de la sécurité PDF : Bonnes pratiques RGPD & CCPA
Minimisation des données et Protection dès la conception (RGPD)
Le RGPD exige que les responsables de traitement mettent en œuvre des mesures techniques et organisationnelles appropriées afin que, par défaut, seules les données personnelles nécessaires à chaque finalité spécifique soient traitées. En utilisant PDF Agile—notre outil PDF IA local‑first hypothétique—vous pouvez répondre à cette exigence en :
Traitant les documents hors ligne : Parce que PDF Agile exécute les modèles IA localement, les données personnelles restent sur l'appareil de l'utilisateur. Il n'y a pas de transmission par défaut vers des serveurs externes, garantissant que seules les données que vous utilisez délibérément sont traitées. Cela s'aligne avec l'exigence du RGPD selon laquelle les données personnelles ne doivent pas être accessibles à un nombre indéfini de personnes.
```Consentement explicite pour l'analyse : Si vous choisissez d'activer la synchronisation cloud optionnelle ou les analyses d'utilisation, l'outil doit demander un consentement clair et expliquer quelles données seront transmises. Les utilisateurs peuvent refuser de partager des données, satisfaisant ainsi à l'exigence de ne traiter que les données personnelles nécessaires.
Contrôles de conservation des données : PDF Agile doit fournir des journaux locaux des interactions IA et permettre aux utilisateurs de supprimer ou d'exporter ces journaux. Étant donné que les données ne vont jamais sur les serveurs du fournisseur par défaut, la suppression est immédiate et vérifiable.
California Consumer Privacy Act (CCPA)
La CCPA accorde aux consommateurs le droit de savoir quelles informations personnelles sont collectées à leur sujet, de supprimer leurs informations personnelles, de refuser leur vente ou leur partage et d'éviter toute discrimination pour l'exercice de ces droits. PDF Agile aide les organisations à se conformer à ces exigences en :
Traitement transparent des données : Lorsqu'il est utilisé localement, PDF Agile ne collecte aucune donnée personnelle, il n'y a donc rien à vendre ou à partager. Si des fonctionnalités cloud optionnelles sont activées, l'outil doit fournir un avis de confidentialité clair listant les catégories de données collectées et les finalités de la collecte.
Suppression sur demande : Étant donné que le traitement IA s'effectue localement, les demandes de suppression peuvent être honorées immédiatement. Si les documents sont synchronisés vers un stockage cloud chiffré, l'utilisateur contrôle les clés de chiffrement ; la suppression de la clé supprime effectivement les données, conformément au droit à la suppression.
Refus de partage des données : L'architecture par défaut empêche déjà le partage de données. Les seules données transmises — les sauvegardes chiffrées — ne le sont que si l'utilisateur y consent. Cela satisfait au droit de refus.
Traitement des Catégories Sensibles de Données
L'article 9 du RGPD couvre les catégories spéciales de données (par exemple, les informations de santé, les opinions politiques), tandis que la CCPA met l'accent sur la protection des catégories telles que les numéros de sécurité sociale et les données financières. Pour traiter ces types de données de manière sécurisée dans les flux de travail IA :
Rédaction locale : Utilisez des outils de rédaction IA locaux pour détecter et supprimer définitivement les données sensibles avant tout partage ou analyse. L'outil de rédaction VeryPDF démontre que le traitement hors ligne peut détecter et supprimer les informations sensibles sans les exposer à des serveurs externes. Les étapes incluent l'analyse du PDF à la recherche de tokens sensibles, la révision des sections signalées et l'application de rédactions permanentes. Cela garantit que les données sensibles n'entrent jamais dans le modèle IA et ne peuvent donc pas être divulguées ou déduites.
Tokenisation : Lorsque la synthèse ou la traduction nécessite du contexte, remplacez les valeurs sensibles par des jetons ([NAME_1], [EMAIL_1], etc.) comme recommandé par les outils de préservation de la confidentialité. Le guide PrivacyScrubber montre que les jetons déterministes permettent au système de fournir une sortie significative tout en préservant l'anonymat. Une fois le traitement terminé, les jetons peuvent être réinsérés dans le document localement.
Accès par moindre privilège : Limitez les personnes pouvant exécuter des analyses IA sur les PDF. Même au sein d'une organisation, réservez les fonctionnalités d'IA au personnel autorisé et conservez des journaux d'audit.
Comment sécuriser les fichiers PDF avec le mode de chiffrement IA hors ligne
Le mode de chiffrement IA hors ligne de PDF Agile propose trois étapes pour garantir que le traitement IA s'effectue localement et que les résultats soient chiffrés avant de quitter votre appareil. Ce mode s'inspire d'outils axés sur la confidentialité comme VeryPDF Smart Redact et d'architectures locales-first sur GitHub.

Étape 1 – Activer le mode hors ligne et vérifier l'absence d'activité réseau
Déconnecter ou restreindre le réseau : Utilisez le pare-feu de votre système d'exploitation ou le « Mode Avion » intégré de PDF Agile pour bloquer les connexions réseau. Cela garantit que les modèles d'IA ne peuvent pas appeler d'API externes. Le guide de caviardage VeryPDF souligne que le traitement hors ligne maintient les fichiers entièrement au sein de votre réseau.
Vérifier le statut hors ligne : PDF Agile doit afficher un indicateur confirmant que le mode hors ligne est actif. Vous pouvez tester en désactivant temporairement le pare-feu ; l'indicateur doit changer si une tentative d'appel réseau est effectuée. Dans une architecture locale-first, aucun paquet sortant ne doit être observé.
Étape 2 – Effectuer les tâches IA localement
Charger les modèles IA en mémoire : PDF Agile intègre des modèles IA pour la synthèse, la traduction et la conversion ; ils se chargent en mémoire depuis le stockage local lorsque le mode hors ligne est actif. L'absence d'appels externes garantit la conformité aux exigences de minimisation des données.
Exécuter les fonctions IA sur votre document : Utilisez le Créateur de PDF IA pour générer un résumé ou convertir un PDF en Word. Étant donné que le Convertisseur PDF en Word IA fonctionne entièrement sur votre appareil, la conversion est rapide et privée. L'OCR local utilise Tesseract.js, similaire à Simple VaultPDF.
Appliquer éventuellement un caviardage : Si votre document contient des informations sensibles, exécutez un caviardage IA local. Le guide VeryPDF présente un flux de travail simple : charger le PDF, laisser l'IA identifier les données sensibles, réviser et appliquer les caviardages. Supprimer les données sensibles avant la conversion ou la synthèse évite toute divulgation accidentelle.
Étape 3 – Chiffrer et exporter
Chiffrez votre sortie : Après traitement, chiffrez le fichier PDF ou Word obtenu à l'aide d'un chiffrement standard de l'industrie (ex. AES‑256). De nombreux outils locaux permettent de définir un mot de passe ou d'exporter vers un ZIP chiffré. Cela correspond à la recommandation de VeryPDF de supprimer définitivement les informations confidentielles et d'éviter toute exposition à des tiers.
Conservez les clés de chiffrement localement : Gardez les clés de chiffrement sur votre appareil ou dans un gestionnaire de mots de passe sécurisé. Évitez de les stocker avec le fichier chiffré ; cela garantit que même si quelqu'un accède au fichier, il ne peut pas le déchiffrer. Cette pratique répond à l'exigence du CCPA de protection contre le partage non autorisé et s'aligne sur le principe de minimisation des données du RGPD.
Conseils opérationnels supplémentaires
Audit et journaux : Activez la journalisation d'audit pour enregistrer qui accède à PDF Agile et quelles actions ils effectuent. Conservez les journaux localement et utilisez-les pour les rapports de conformité.
Mises à jour régulières : Maintenez vos modèles d'IA locaux et vos bibliothèques de chiffrement à jour. Les vulnérabilités des logiciels obsolètes peuvent compromettre la confidentialité même lorsque le traitement est local.
Formation des employés : Formez le personnel à l'utilisation sécurisée de l'IA. UpGuard souligne que la sensibilisation des employés réduit les erreurs involontaires.
Conclusion
L'intelligence artificielle offre des outils puissants pour organiser les PDF—résumer des rapports, convertir des documents et extraire des données. Pourtant, la commodité de l'IA cloud comporte des risques cachés importants : la conservation des données et la mémorisation des modèles peuvent entraîner une fuite d'informations sensibles. Des incidents réels, comme la fuite ChatGPT de Samsung, montrent que même les grandes entreprises peuvent exposer par inadvertance du code propriétaire. Les cadres réglementaires comme le RGPD et le CCPA exigent la confidentialité dès la conception, la minimisation des données et la possibilité pour les utilisateurs de savoir, de supprimer et de refuser.
Une solution PDF IA locale comme PDF Agile répond à ces défis en garantissant que tout le traitement s'effectue sur l'appareil de l'utilisateur. Des projets GitHub tels que Simple VaultPDF et PDF Editor Offline démontrent que l'édition complète de PDF et les fonctionnalités d'IA sont réalisables sans aucune interaction cloud. La mise en œuvre d'une architecture locale, de la tokenisation, de la rédaction hors ligne et de l'exportation chiffrée permet aux organisations d'exploiter les avantages de l'IA tout en maintenant la conformité et en protégeant les secrets commerciaux. Le mode de chiffrement IA hors ligne en trois étapes fournit un guide opérationnel pratique pour des workflows PDF sécurisés. En adoptant ces pratiques, les entreprises peuvent intégrer l'IA en toute confiance dans leur pipeline de traitement de documents sans sacrifier la confidentialité ni exposer leur espace de travail numérique à des risques invisibles.