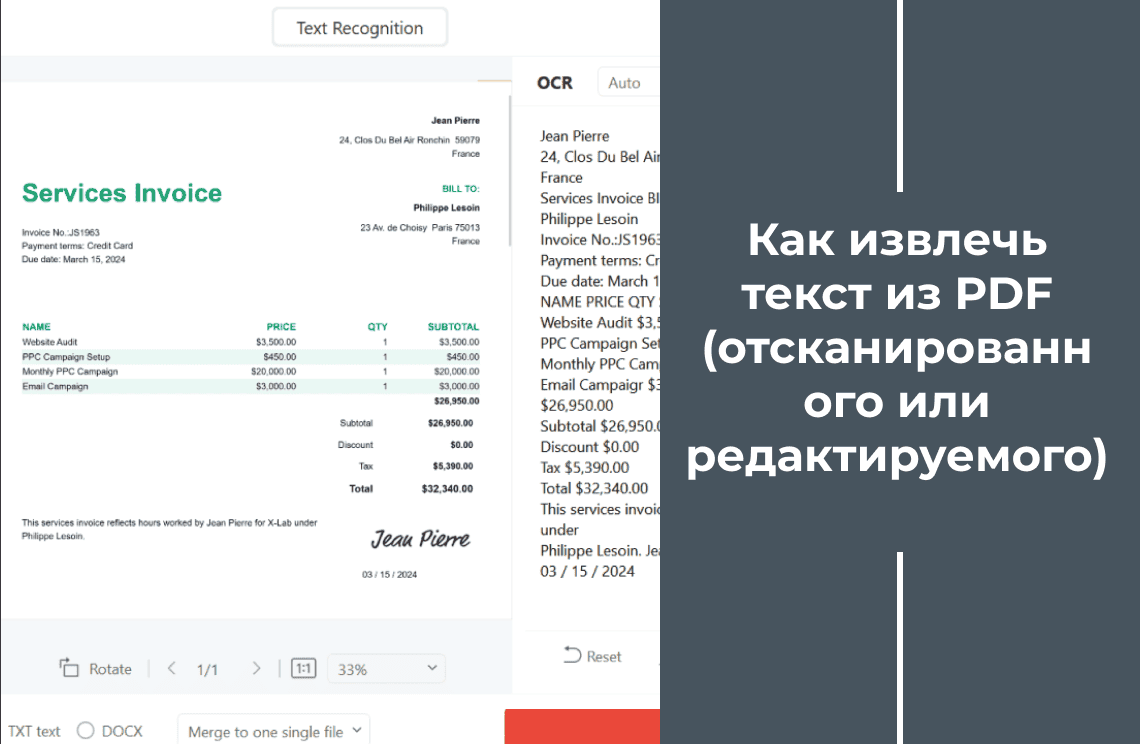
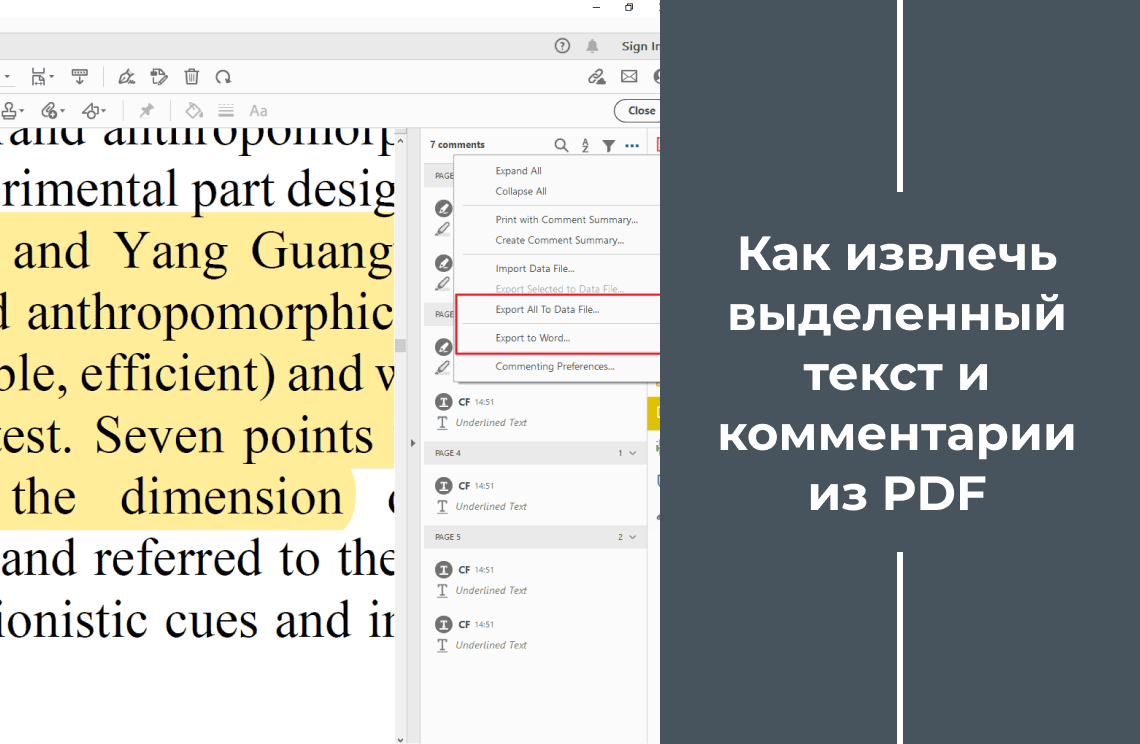
Извлечение текста из PDF‑документов стало необходимым шагом для множества задач — таких как исследовательская работа, анализ данных и управление контентом. Инструмент для извлечения текста из PDF может значительно упростить процесс получения и использования текстовой информации из документов PDF. Изучите важность извлечения текста из PDF, преимущества применения технологии OCR (Оптическое распознавание символов, Optical Character Recognition), а также альтернативные методы извлечения текста без функции OCR.
Давайте упростим процесс, представив пять эффективных способов извлечения текста из любого PDF‑файла — с OCR для изображений и без OCR для цифровых файлов. Эти решения подходят для разных потребностей и уровней технической подготовки — от быстрого ручного копирования до пакетной обработки нескольких документов. Никаких сложных терминов и лишних действий — только понятные и практичные методы, которые работают легко.
В итоге вы точно узнаете, как это делать:
- Преобразовывать отсканированные PDF в редактируемый текст
- Сохранять форматирование при экспорте в Word или Excel
- Извлекать текст из нескольких файлов одновременно
- Работать с защищёнными или запароленными документами
- Выбирать подходящий инструмент для конкретной задачи
Хватит перепечатывать — начните извлекать данные эффективно. Приступим!
Важность извлечения текста из PDF‑файлов
Извлечение текста из PDF‑документов позволяет проще доступаться к информации, содержащейся в файле. Это может значительно повысить эффективность рабочего процесса при поиске конкретных ключевых слов, анализе содержания или повторном использовании текста в других документах. Преобразуя текст PDF в более редактируемый и поисковый формат, пользователи экономят время и повышают производительность.
Технология OCR (Оптическое распознавание символов — Optical Character Recognition) является мощным инструментом для извлечения текста из отсканированных PDF или изображений. Тем не менее, существуют и альтернативные методы извлечения текста из PDF‑файлов, не требующие использования OCR. Они полезны в тех случаях, когда OCR может быть недоступна или излишня. Изучив эти дополнительные методы, вы расширите свой набор инструментов для извлечения текста из PDF и сможете выбрать наиболее подходящий вариант.
Разные методы извлечения текста из PDF с и без OCR
Хотя извлечение текста из PDF является распространённой, но порой раздражающей задачей — особенно при работе с отсканированными документами, защищёнными файлами или плохо отформатированным содержимым. Если вы студент, который собирает материалы для исследования, профессионал, работающий с контрактами, или просто пользователь, пытающийся отредактировать PDF, невозможность скопировать текст может забирать драгоценное время и усилия.
Работа с PDF‑файлами часто требует извлечения текста для редактирования или повторного использования. Независимо от того, содержит ли ваш документ поисковый текст или отсканированные страницы, ниже представлены четыре простых способа выполнить эту задачу — с использованием и без использования технологии OCR.
Метод 1: Извлечение текста с помощью OCR‑функции PDF Agile
OCR (оптическое распознавание символов) — незаменимая технология для отсканированных или изображённых PDF‑документов. Встроенная OCR‑функция PDF Agile точно преобразует изображения с текстом в редактируемое и поисковое содержимое, сохраняя форматирование. Эта мощная возможность экономит часы ручного ввода и отлично работает даже с низкокачественными сканами.
Шаги :
1. Откройте PDF Agile и загрузите отсканированный PDF‑файл.
2. Нажмите кнопку «OCR» на панели инструментов.

3. Текст из вашего документа будет извлечён.
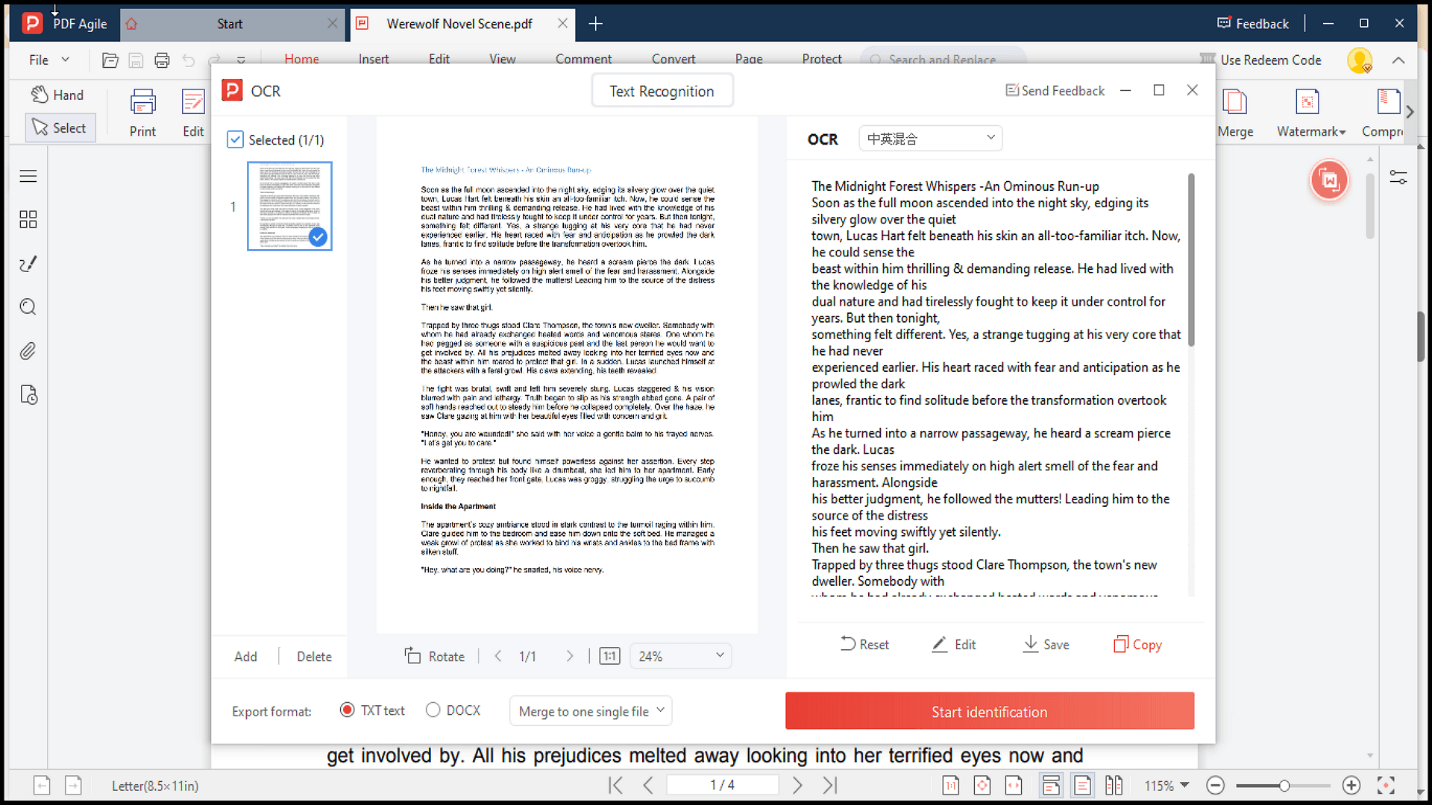
4. Выберите формат вывода — TXT или DOCX.
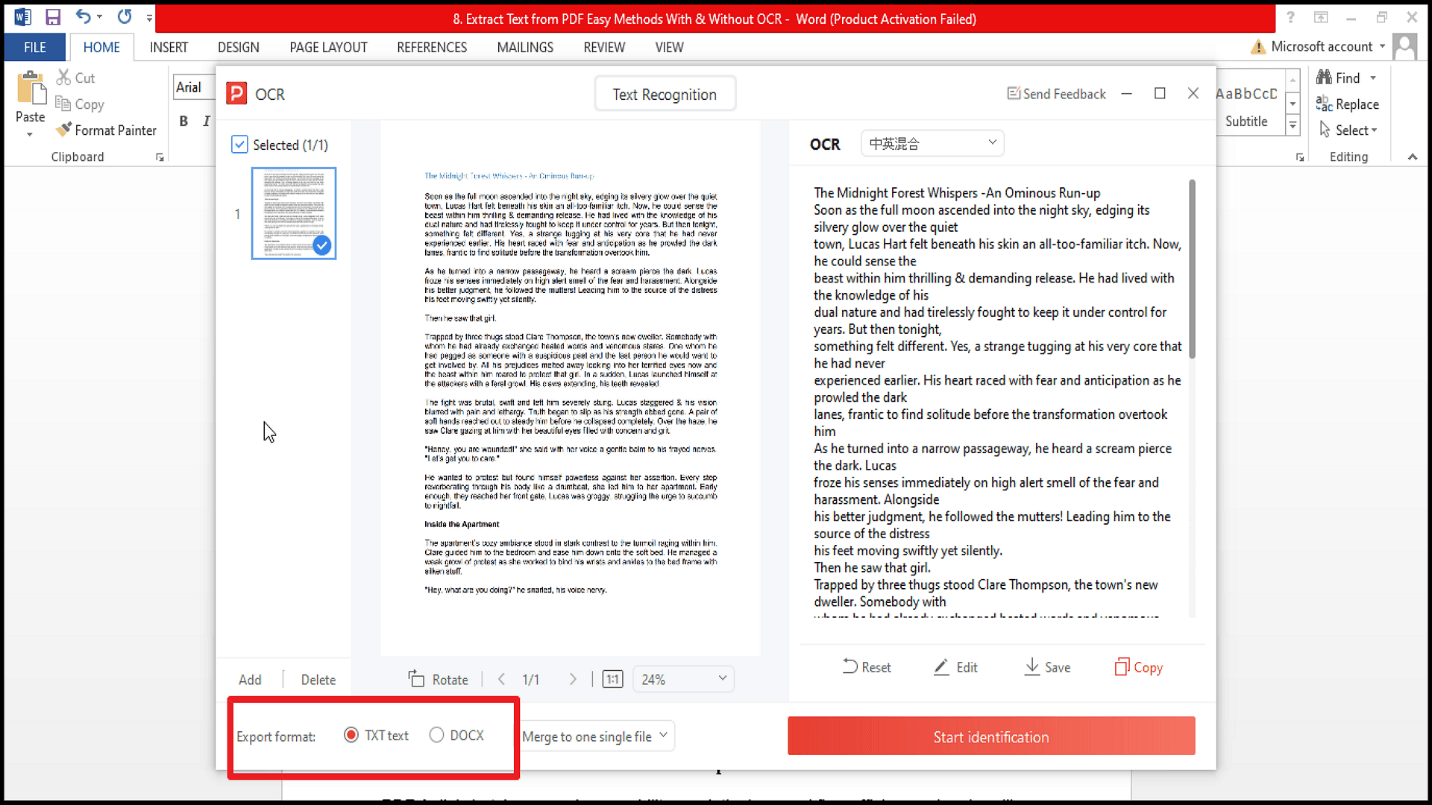
5. Вы можете редактировать или сохранить текст.
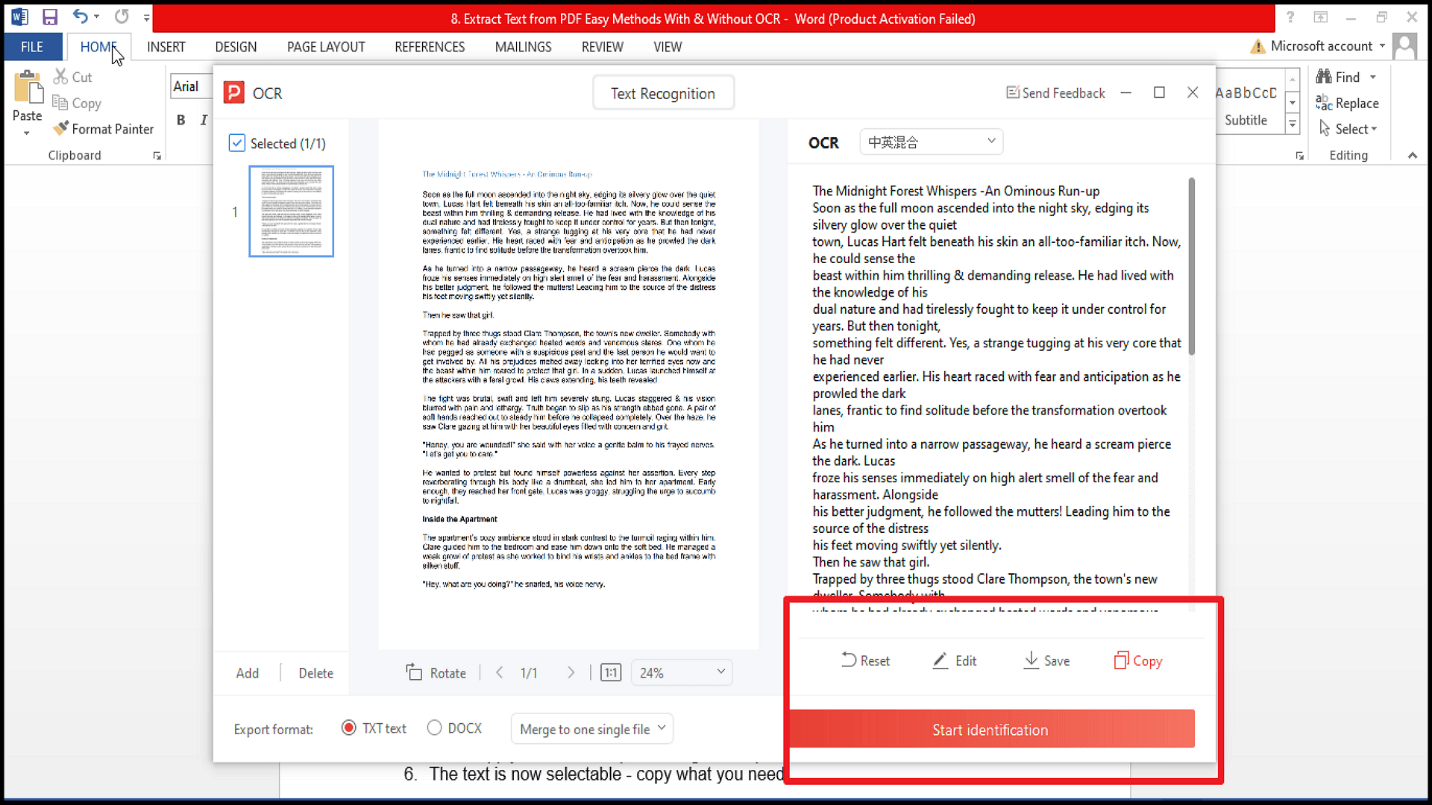
6. Теперь текст доступен для выделения — скопируйте нужные фрагменты!
Метод 2: Извлечение текста с помощью функции экспорта PDF Agile
Функция экспорта в PDF Agile — самый простой способ извлечь текст из стандартных, текстовых PDF‑файлов. В отличие от OCR, которая обрабатывает изображения, этот метод мгновенно конвертирует доступный для чтения текст PDF в редактируемые форматы, сохраняя структуру абзацев и базовое форматирование.
Шаги :
1. Откройте интерфейс PDF Agile и перейдите в раздел File в левом верхнем углу.
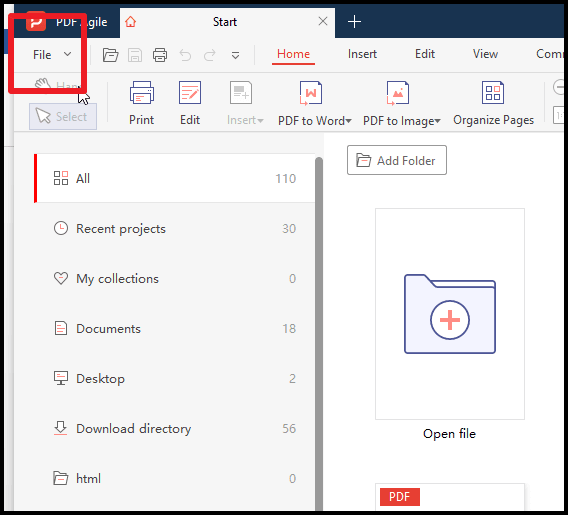
2. Нажмите на значок Export PDF и выберите формат вывода для извлечения текста.
3. Появится всплывающее окно для конвертации текста в нужный формат.
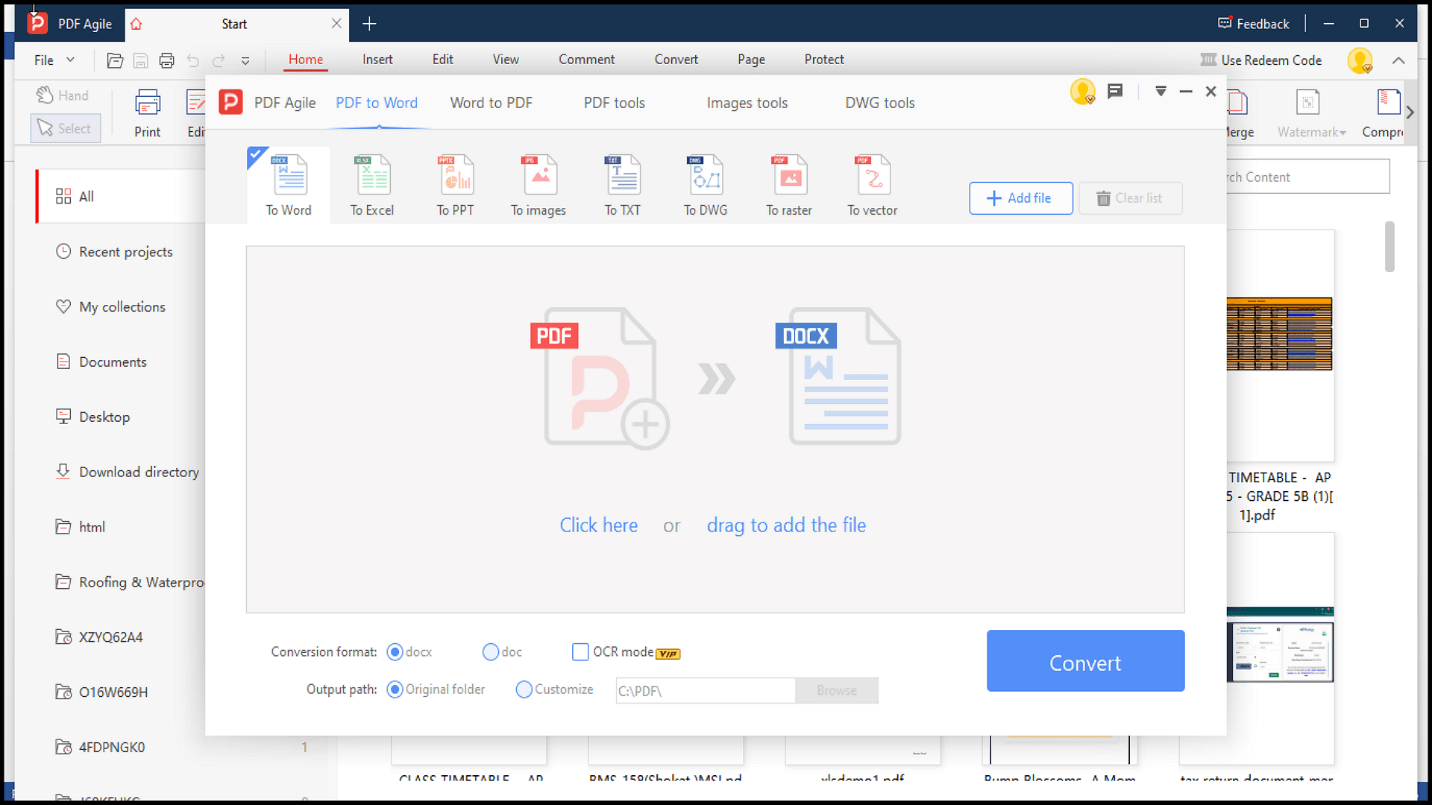
4. Выберите раздел Add File и загрузите PDF‑документ.
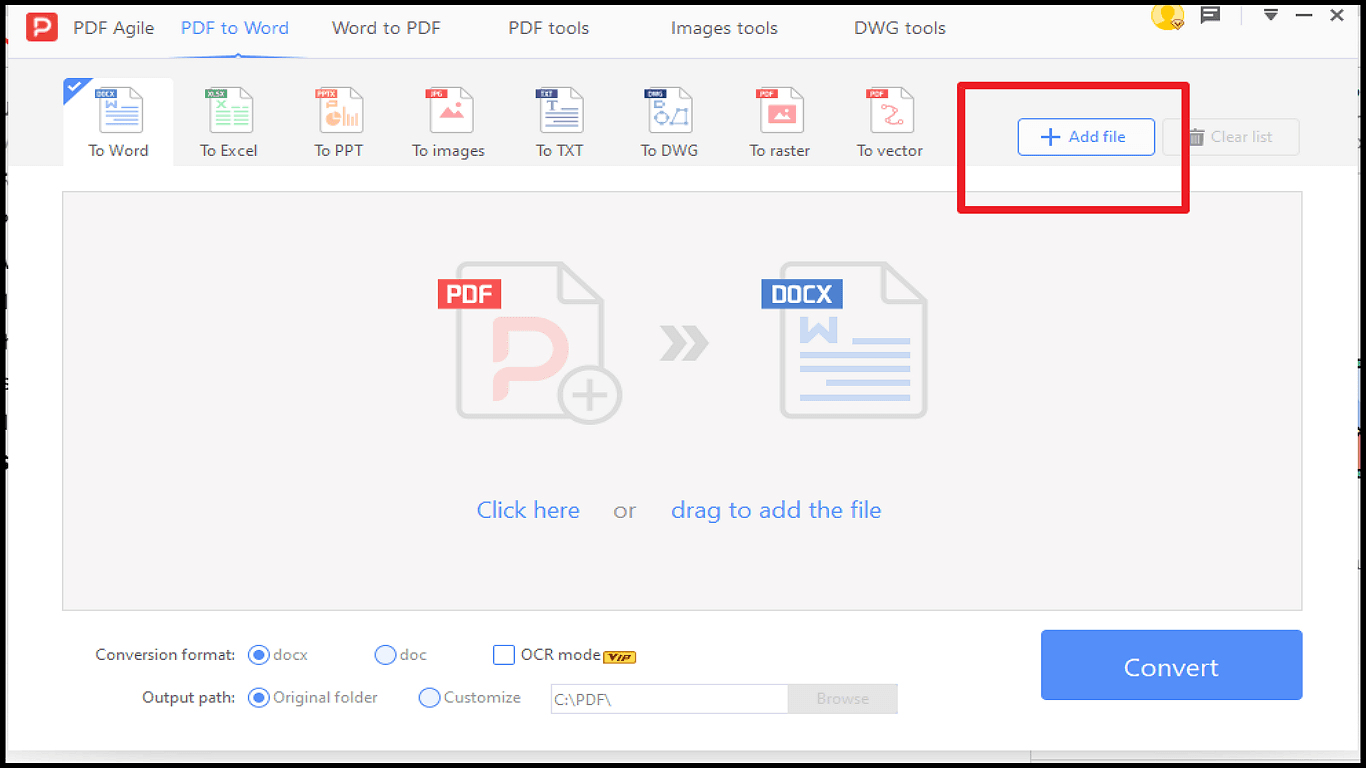
5. Нажмите Convert и подождите несколько секунд до завершения конвертации.
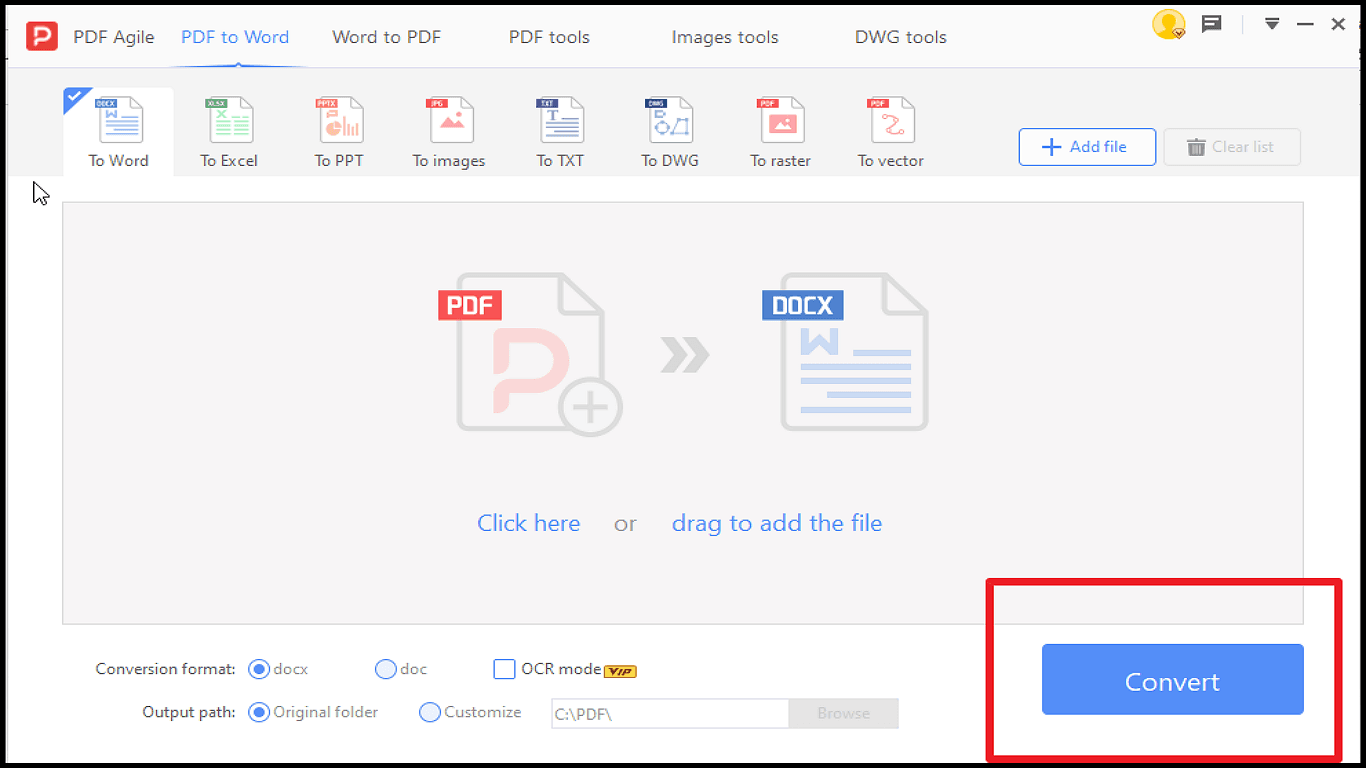
6. Ваш файл готов к извлечению текста. Откройте его в редакторе PDF Agile и начните работу.
Метод 3: Ручное извлечение текста в режиме редактирования
Режим прямого редактирования в PDF Agile предоставляет точный контроль для быстрого и избирательного копирования текста из стандартных PDF‑файлов. Этот метод идеален, если вам нужно всего несколько абзацев или фрагментов текста, а не весь документ. Дополнительным преимуществом является предварительный просмотр форматирования в реальном времени. Интерфейс по функциональности похож на знакомые текстовые редакторы, что делает его удобным в использовании.
Шаги :
1. Откройте PDF в PDF Agile и включите режим «Edit».
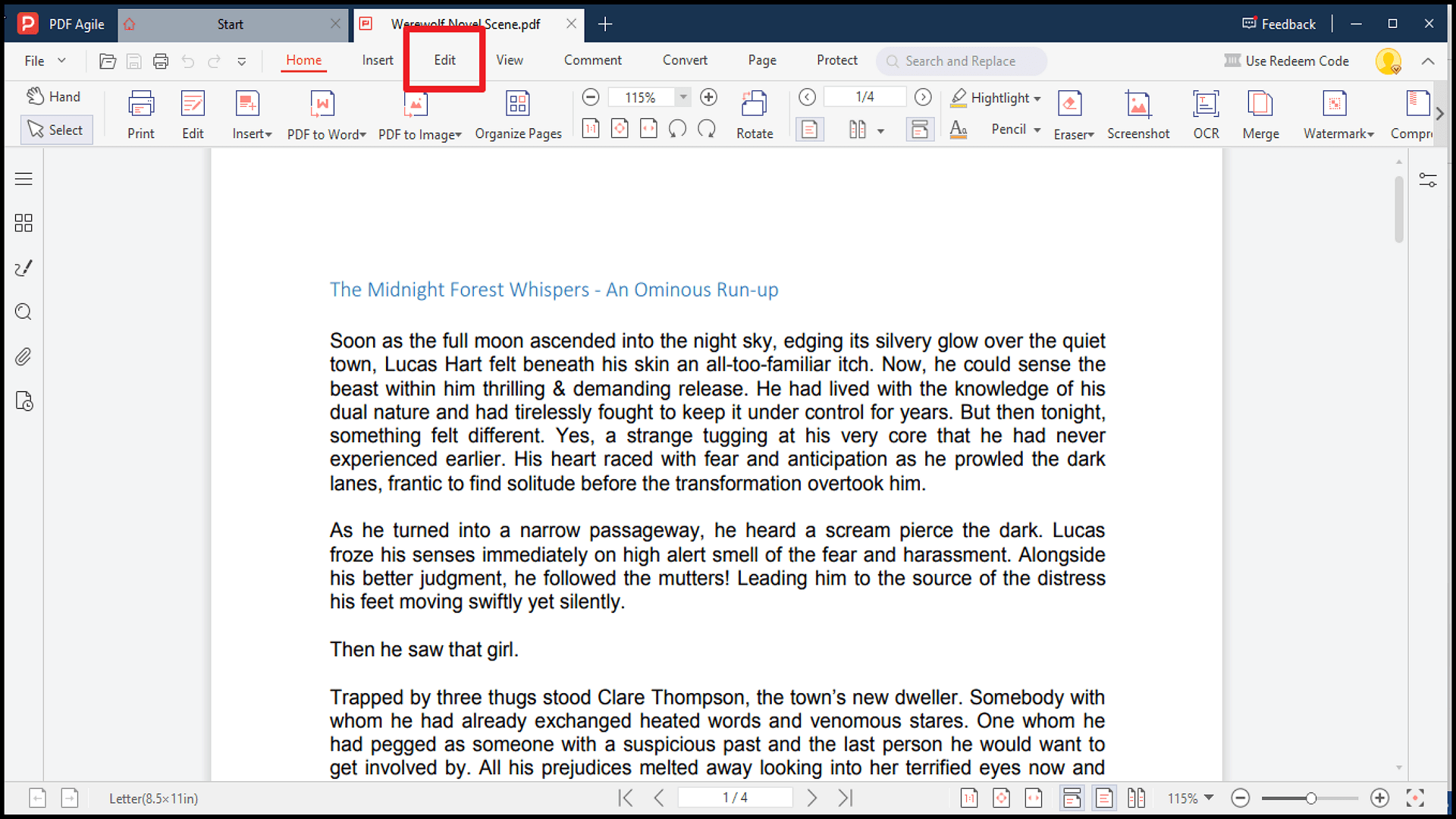
2. Щёлкните правой кнопкой мыши по нужному тексту и выберите Copy или нажмите Ctrl + C.

3. Вставьте текст в любое внешнее приложение.
4. Используйте панель форматирования, чтобы изменить шрифт или размер при необходимости.
Метод 4: Извлечение текста из PDF‑изображений в Adobe Acrobat
Расширенный движок OCR в Adobe Acrobat справляется с обработкой сложных макетов документов и низкого разрешения сканов с высокой точностью. Его ИИ‑распознавание поддерживает более 100 языков и лучше, чем многие аналоги, сохраняет таблицы, колонки и сложное форматирование. Однако для использования этой функции необходимо оплаченное подписное издание.
Шаги :
1. Откройте PDF в Adobe Acrobat (не в версии Reader).
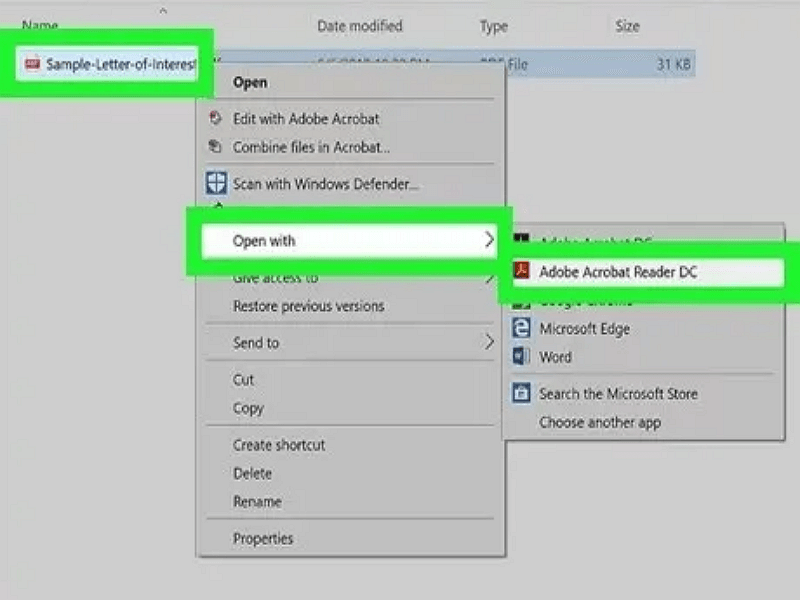
2. Перейдите в меню «Правка» (Edit) и нажмите «Выделить всё» (Select All).
3. Выделите нужный текст курсором и скопируйте его. Можно также щёлкнуть правой кнопкой мыши и выбрать «Копировать» (Copy).
Продвинутые советы по извлечению текста
- Регулярные выражения:Используйте регулярные выражения (регексы), чтобы искать определённые шаблоны или форматы в извлечённом тексте. Этот расширенный приём позволяет извлекать текст более точно и эффективно, задавая пользовательские правила поиска.
- Пакетная обработка:Рассмотрите возможность использования инструментов пакетной обработки, чтобы автоматизировать процесс извлечения, если у вас много PDF‑файлов. Это поможет сэкономить время и усилия при работе с несколькими документами одновременно.
- Извлечение метаданных :Пробуйте извлекать не только текстовое содержание, но и метаданные, встроенные в PDF‑документы. Эти дополнительные данные могут раскрыть автора, дату создания и другие сведения, что повышает понимание структуры и происхождения документа.
- Интеграция с системами управления документами :Интегрируйте инструмент для извлечения текста с системами управления документами или облачными сервисами хранения, чтобы автоматически сохранять извлечённые версии. Это улучшает доступность и организацию данных.
Эти продвинутые рекомендации помогут оптимизировать ваш процесс извлечения текста из PDF‑файлов и повысить точность, эффективность и удобство управления извлечёнными данными.
Часто задаваемые вопросы (FAQs)
Как извлечь текст из отсканированного PDF?
Вы можете использовать инструменты OCR (оптического распознавания символов), такие какPDF Agile, чтобы преобразовать отсканированные изображения в редактируемый текст
Почему мой PDF не позволяет скопировать текст?
- Это может быть отсканированный или изображённый PDF (используйте OCR).
- Файл может быть защищён паролем (сначала разблокируйте его с разрешения владельца).
- Текст может быть недоступен для выделения(попробуйте ручное извлечение или OCR).
Как извлечь текст из нескольких PDF файлов сразу?
Используйте пакетную обработку (Batch Processing) в PDF Agile:
- Откройте инструмент «Пакетный режим» (Batch Tool).
- Добавьте ваши PDF‑файлы.
- Выберите «Извлечь текст» (Extract Text).
- Укажите папку для сохранения (Output Folder)
Можно ли скопировать текст из PDF без специального ПО?
Да! Если это цифровой PDF (а не скан):
- Откройте его в Google Диске → щёлкните правой кнопкой мыши → выберите «Открыть с помощью (Open with)» → Google Документы.
- Или используйте Ctrl + C, если текст можно выделить.
Как извлечь текст из PDF, защищённого паролем?
Если у вас есть пароль:
- Откройте PDF‑файл с помощью инструмента, такого как PDF Agile.
- Введите пароль при запросе.
- Экспортируйте или скопируйте текст.
Примечание : Никогда не обходите защиту файла без разрешения.
Почему извлечённый текст выглядит неряшливо?
- Отсканированные PDF: ошибки OCR — попробуйте улучшить качество сканов перед обработкой.
- Цифровые PDF: сложное форматирование (таблицы, колонки) может копироваться некорректно. Используйте «Экспорт в Word (Export to Word)» для лучшего результата.
Заключение
Извлечение текста из PDF‑файлов — как со сканированных изображений, так и из цифровых документов — не обязательно должно быть сложным. С правильными инструментами и методами даже самые «упорные» PDF‑файлы можно быстро преобразовать в редактируемый и пригодный для повторного использования текст.
- Для сканированных PDF: инструменты OCR, например в PDF Agile, надёжно преобразуют изображения в выделяемые данные.
- Для цифровых PDF: встроенные функции экспорта или простое копирование‑вставка помогают экономить время без дополнительного ПО.
- Для массового извлечения: пакетная обработка позволяет работать с несколькими файлами одновременно, что идеально для крупных проектов.
- Для защищённых файлов: защита паролем не обязательно препятствие — существуют законные способы доступа (при надлежащем разрешении).
Всегда выбирайте метод, который соответствует типу документа и вашим целям. Ручное копирование подойдёт, если нужен всего один абзац; автоматический OCR — лучшее решение для архивов со сканами.
Теперь, зная эти приёмы, можно забыть о повторном наборе и наслаждаться плавным извлечением текста. Успешного редактирования!