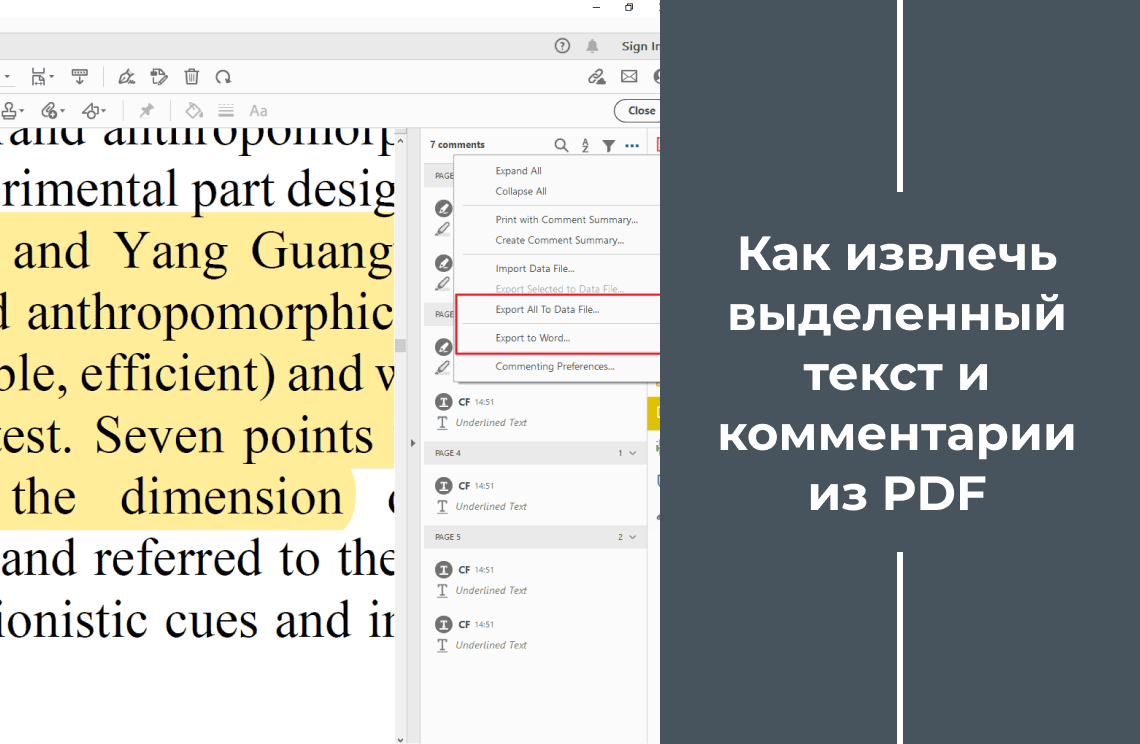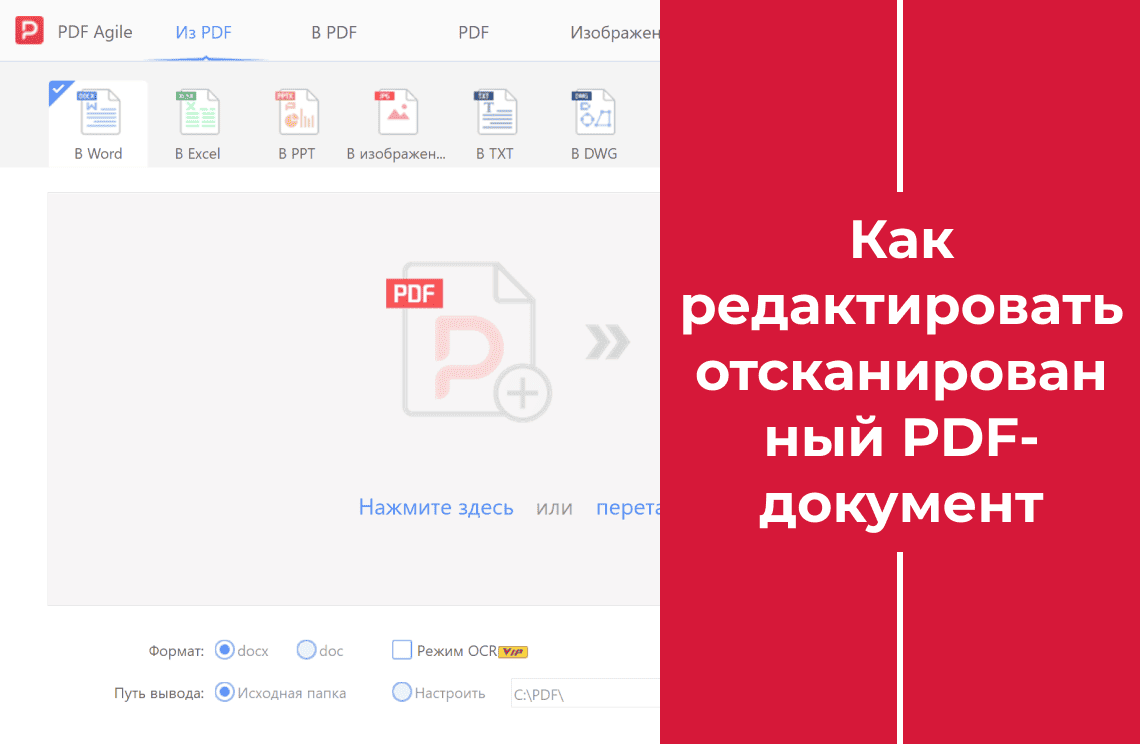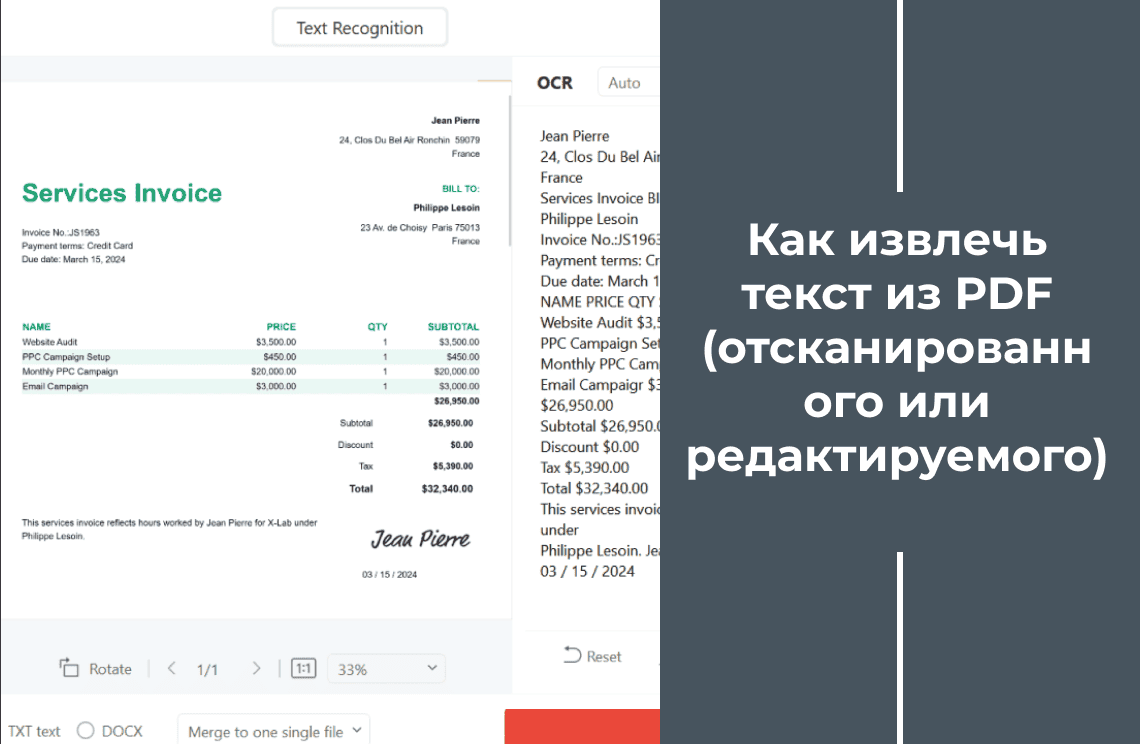
Бывало, что терялись в цифровом лабиринте PDF‑файлов? Текст, который вам так нужен, оказывается заперт в нередактируемом формате, и вы тратите часы на его перепечатку или на неуклюжие попытки скопировать его вручную. Отсканированные документы добавляют ещё больше сложностей — текст скрыт за слоем изображений. Было бы замечательно легко разблокировать ценное содержимое любого PDF — отсканированного или редактируемого — и превратить его в пригодный для работы текст? Представьте, что вы повышаете свою продуктивность, оптимизируете задачи и прощаетесь с рутинной ручной перепечаткой. Это руководство — ваш ключ к побегу из PDF-ловушки! С помощью PDF Agile вы узнаете, как извлечь текст из любого PDF точно и без усилий, экономя своё время и силы. Готовы раскрыть скрытый потенциал своих цифровых документов?
Как извлечь текст из PDF (отсканированного или редактируемого) с помощью PDF Agile?
Для сложных отсканированных PDF или случаев, когда важна максимальная точность, настольная версия PDF Agile предлагает мощное решение с продвинутыми возможностями OCR:
Извлечение текста из отсканированного PDF с помощью PDF Agile
Шаг 1. Скачайте и установите PDF Agile
Перейдите на официальный сайт PDF Agile и загрузите версию, подходящую для вашей операционной системы (Windows или Mac). После загрузки следуйте инструкциям на экране, чтобы установить программу.
Шаг 2. Откройте свой отсканированный PDF
Запустите PDF Agile, в верхнем меню выберите «Файл» → «Открыть» и найдите нужный документ на своём компьютере. Дважды щёлкните по файлу, чтобы открыть его в программе.
Шаг 3. Запуск OCR напрямую
Первый способ. Откройте вкладку «OCR» в интерфейсе PDF Agile и нажмите кнопку «OCR». Программа проанализирует изображения и преобразует встроенный текст в редактируемые символы.
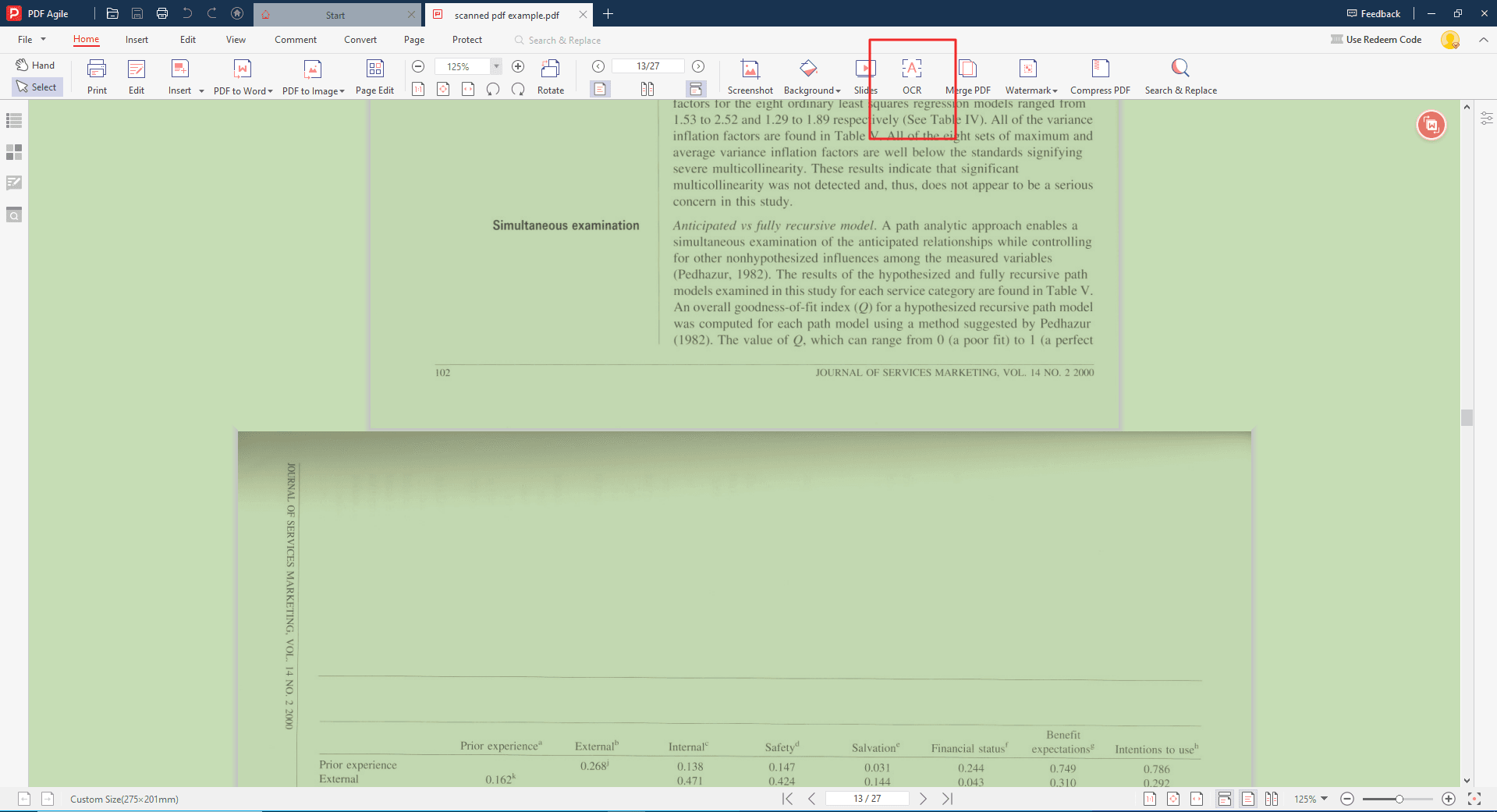
Шаг 4. Альтернативный способ: PDF-в-Word через OCR
Второй способ. Откройте вкладку «Преобразовать» и выберите «PDF в Word». Далее выберите формат (docx, doc) и активируйте OCR-модель. PDF Agile выполнит распознавание текста и создаст редактируемую версию.
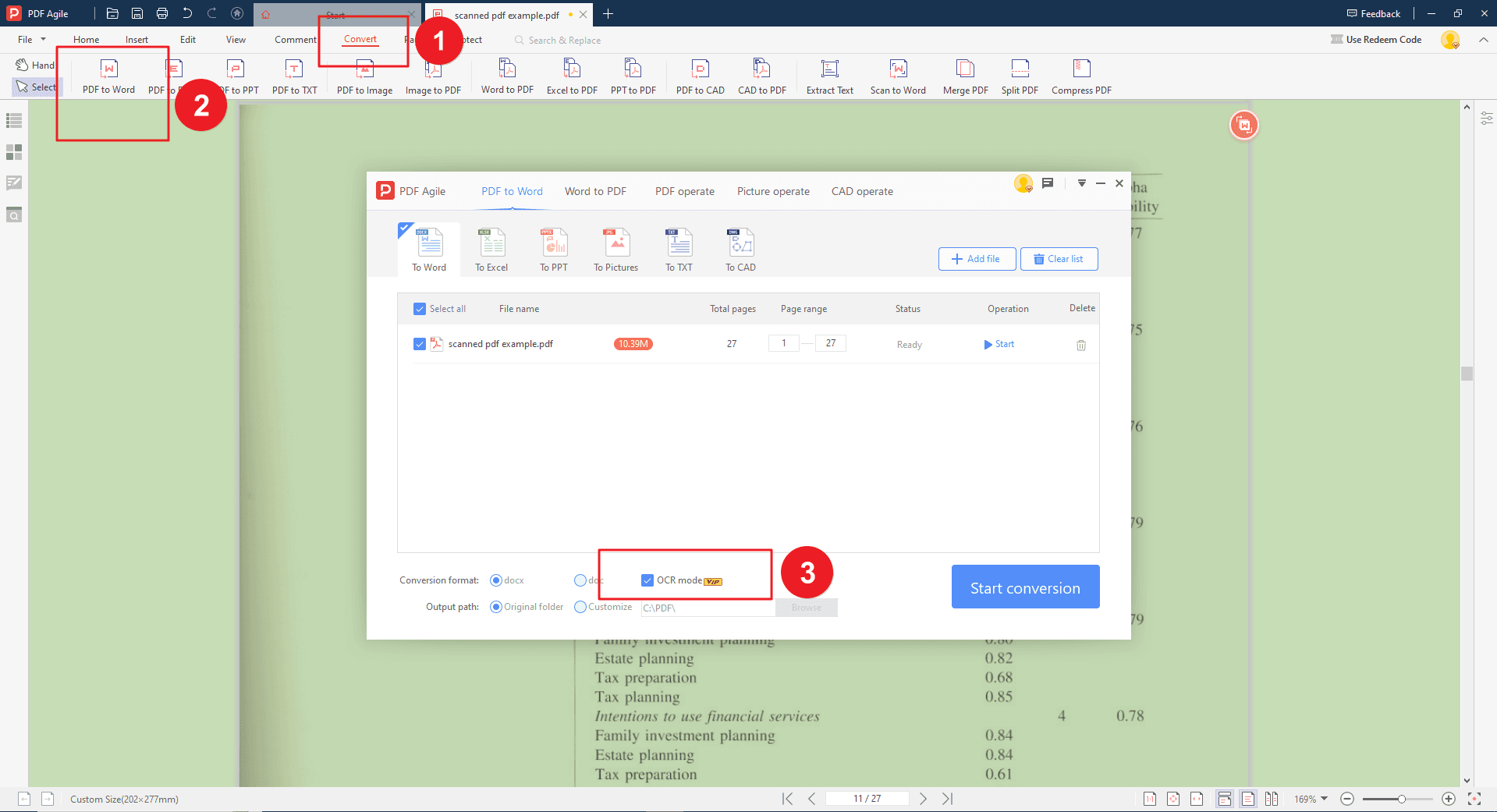
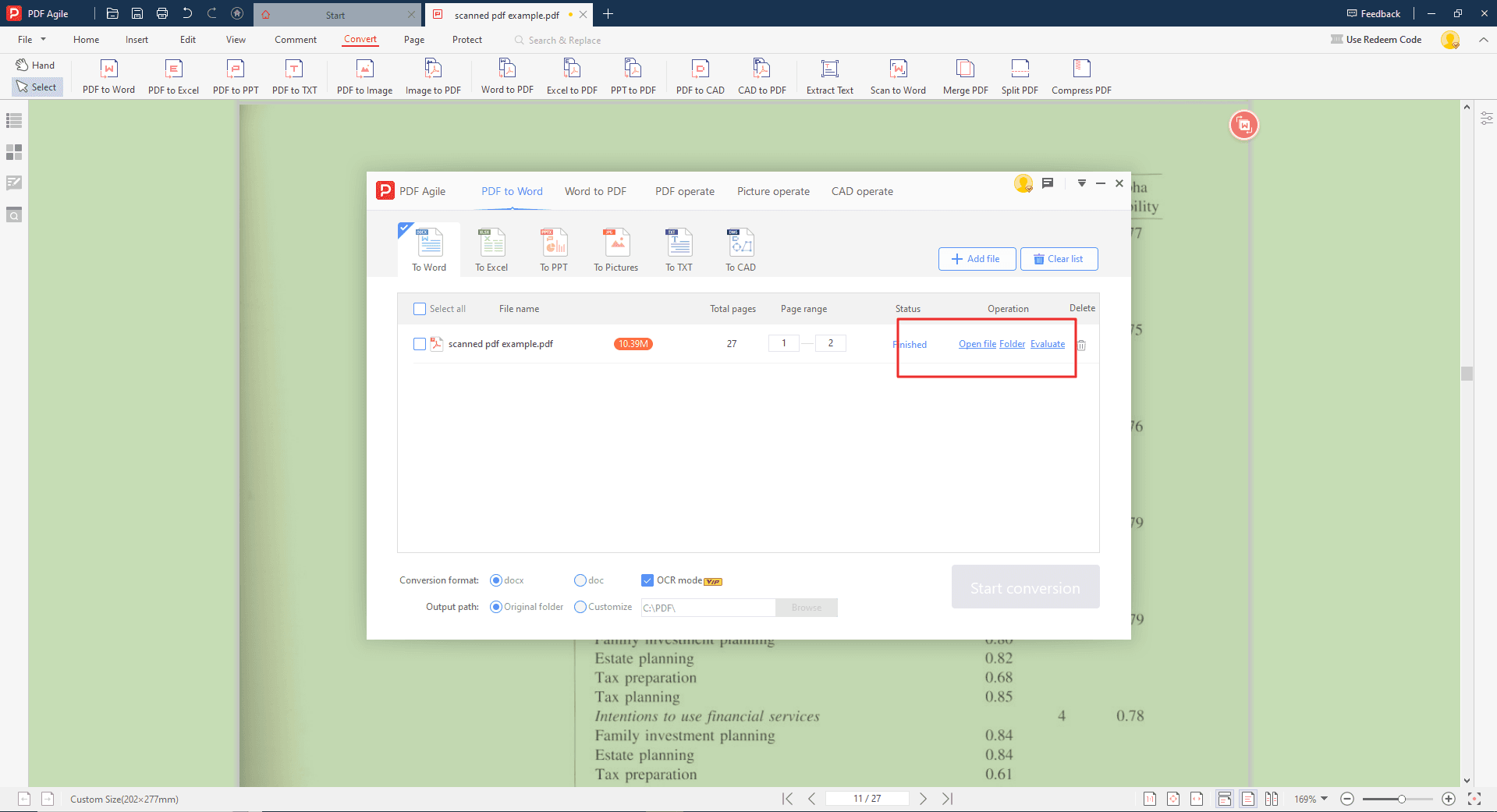
Шаг 5. Запуск конверсии и просмотр документа
После настройки OCR нажмите «Начать» или «Начать преобразование». Процесс может занять некоторое время в зависимости от объёма и сложности документа. По завершении PDF Agile отобразит редактируемую версию, где вы сможете редактировать, копировать или сохранять текст в другом формате.
Извлечение текста из редактируемого PDF с помощью PDF Agile
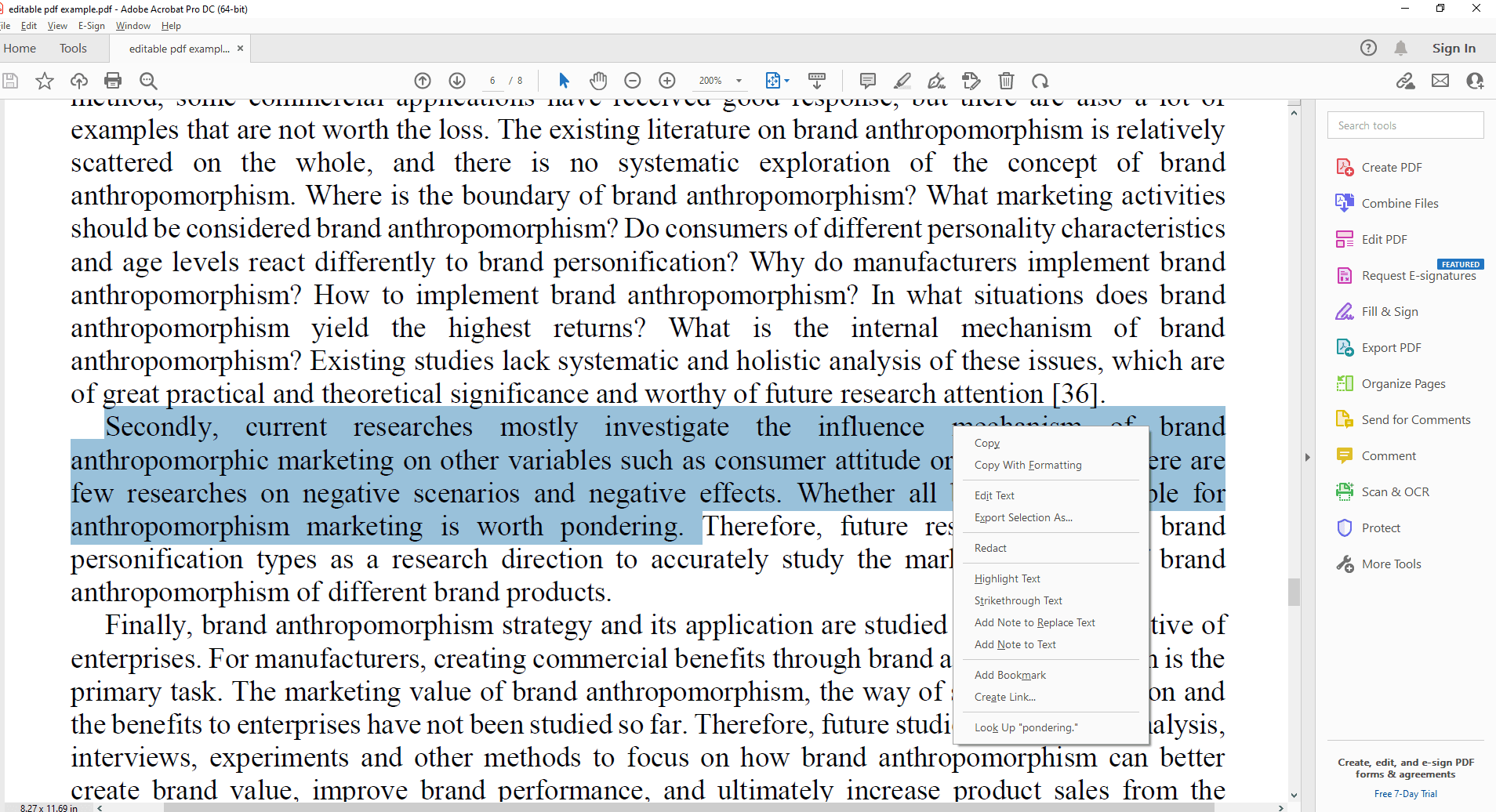
Откройте документ и просто выделите нужный текст. Щёлкните правой кнопкой мыши и выберите «Копировать». Полученный текст можно вставить в текстовый редактор, Word или другое приложение.

Как извлечь текст из отсканированного PDF с помощью Adobe Acrobat?
Ниже приведено подробное руководство по извлечению текста из отсканированных PDF в Adobe Acrobat, основанное на официальных инструкциях:
Извлечение текста из отсканированного PDF с помощью Adobe Acrobat
Шаг 1. Откройте отсканированный PDF
Запустите Adobe Acrobat, выберите в меню «Файл» → «Открыть» и найдите нужный документ.
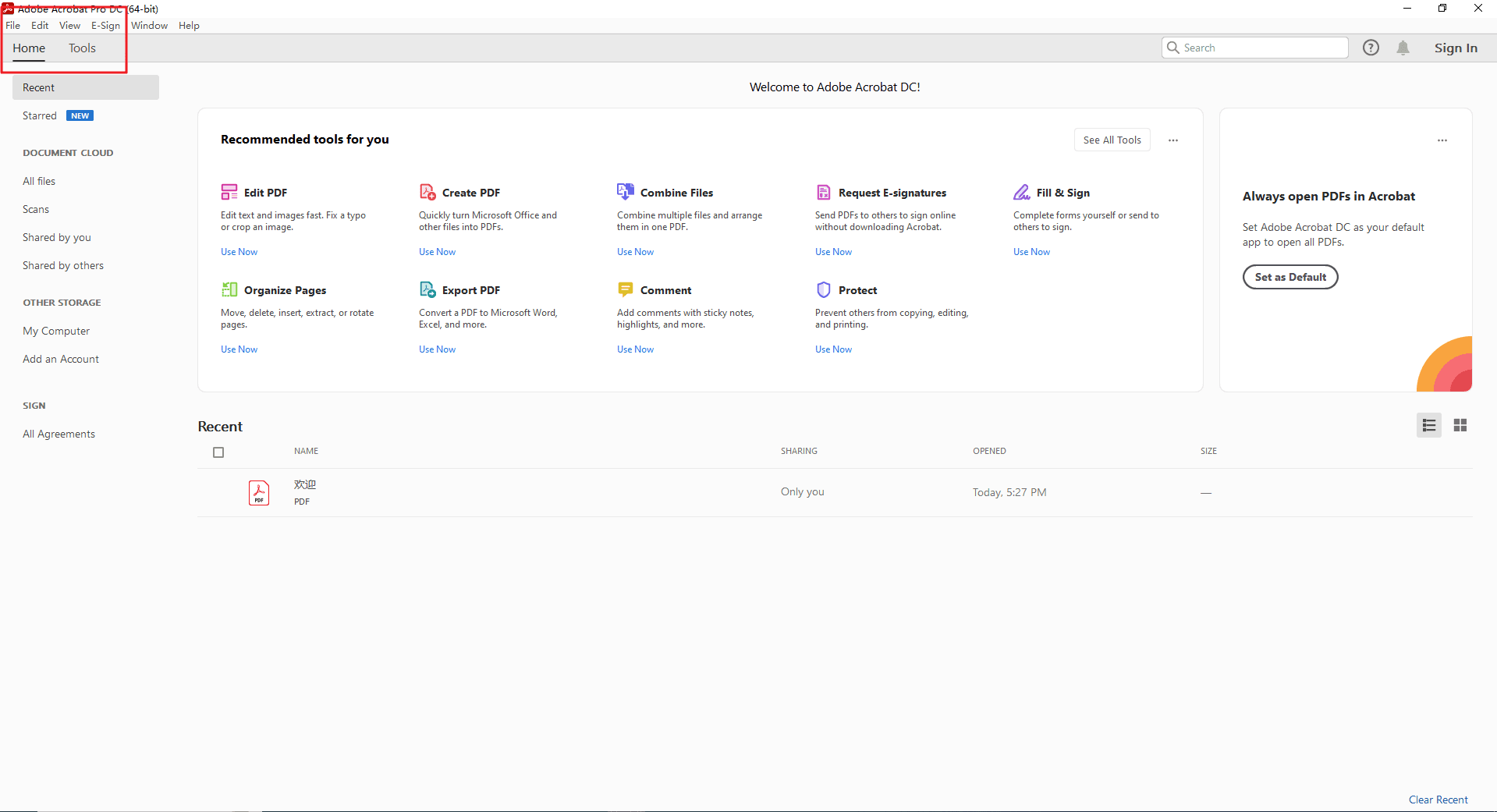
Шаг 2. Запуск функции «Сканирование и OCR»
Первый вариант. Откройте меню инструментов и выберите «Сканирование и OCR». При необходимости настройте язык и диапазон страниц, затем нажмите «ОК», чтобы начать распознавание.

Шаг 3. Альтернативный способ через «Редактирование PDF»
Откройте раздел «Инструменты» → «Редактировать PDF». Если OCR не запускается автоматически, нажмите значок «Распознать текст».
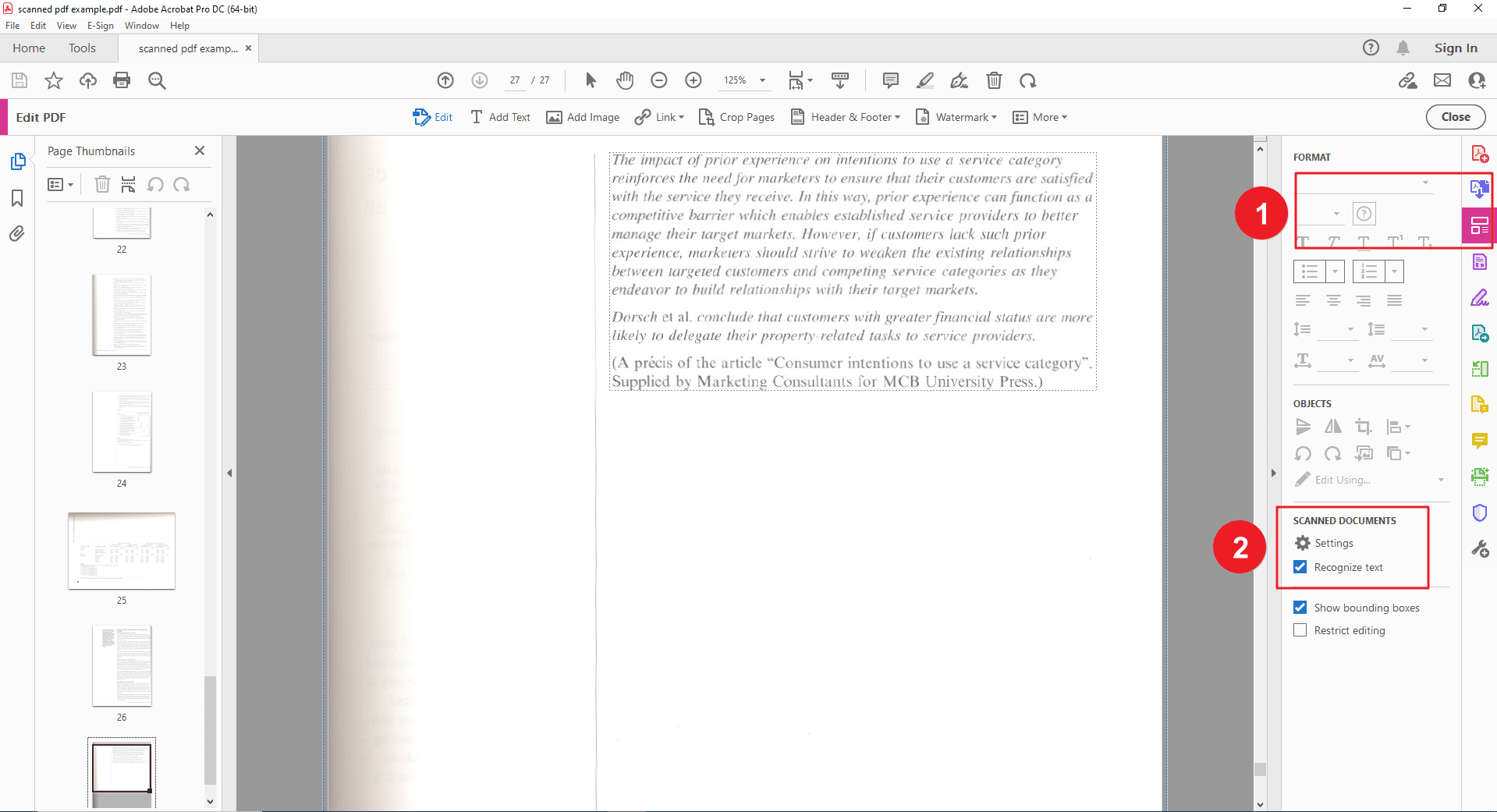
Шаг 4. Извлечение текста после OCR
После распознавания выделите нужный текст, щёлкните правой кнопкой мыши и выберите «Копировать». Вставьте скопированный текст в нужное приложение.
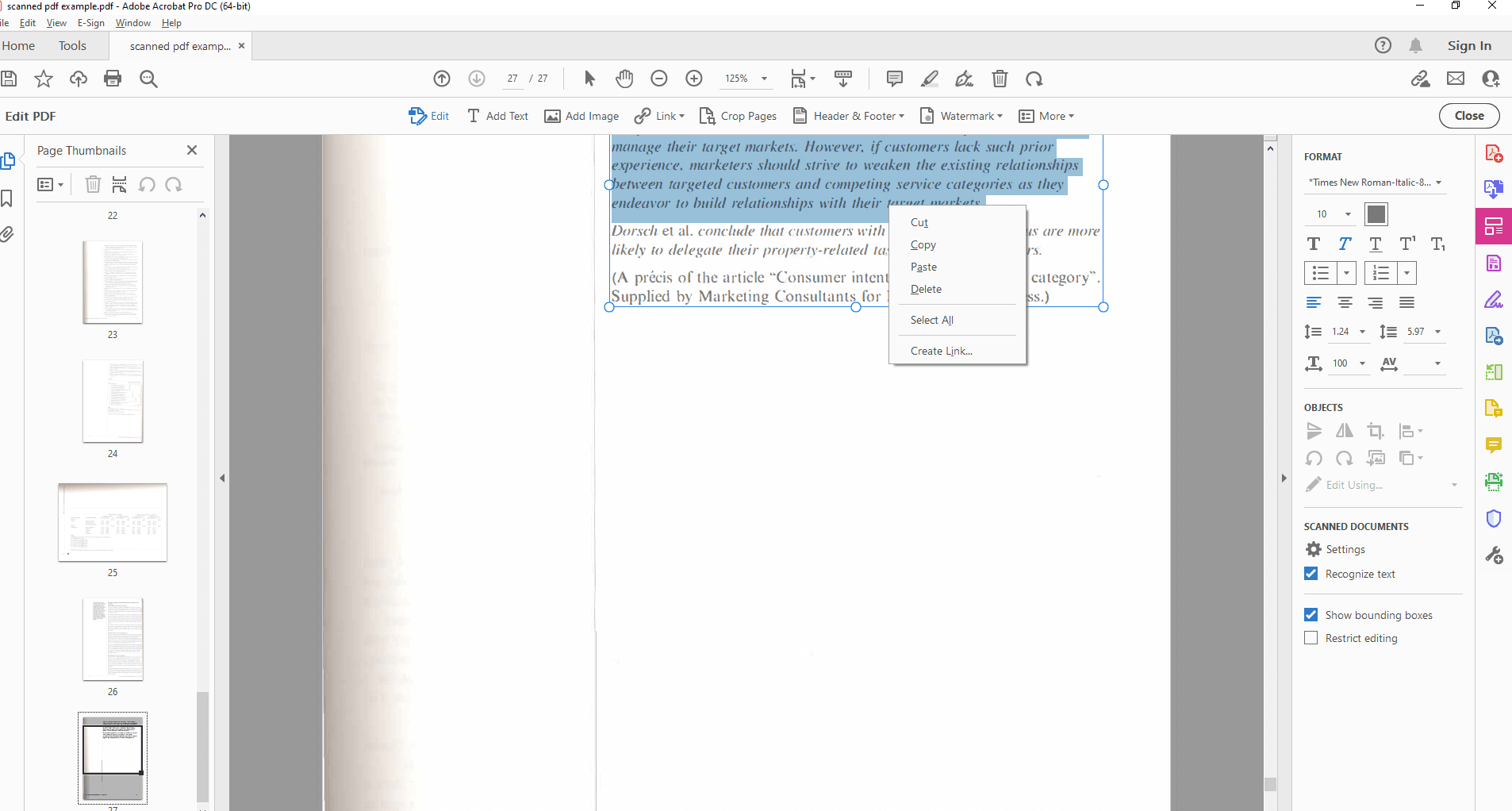
Извлечение текста из редактируемого PDF в Adobe Acrobat
Перейдите к нужному разделу документа, выделите текст, нажмите Ctrl+C (Windows) или Cmd+C (Mac), а затем вставьте его в текстовый редактор.
Преимущества PDF Agile
Лёгкое извлечение: Преодолейте ограничения простого копирования и вставки — используйте интеллектуальные инструменты для быстрого и точного извлечения текста.
Современный OCR: Для отсканированных PDF PDF Agile применяет передовые технологии оптического распознавания текста (OCR), обеспечивая высокую точность и чистоту символов.
Не просто извлечение:Программа позволяет редактировать и форматировать извлечённый текст прямо в документе.
Гибкость: Хотите онлайн-решение для быстрых задач или мощную настольную программу для сложных файлов — PDF Agile предлагает оба варианта.
С помощью PDF Agile вы можете:
Извлекать текст из любого PDF — отсканированного или редактируемого.
Наслаждаться высокой точностью благодаря передовому OCR.
Редактировать и использовать извлечённый текст по своему усмотрению.
Выбирать между онлайн-удобством и мощностью настольной версии.
Часто задаваемые вопросы (FAQ)
Есть ли ограничения у онлайн-конвертеров OCR?
Ограничение размера файла — крупные документы могут не поддерживаться.
Вопросы безопасности — загрузка конфиденциальных файлов в интернет может быть рискованной.
Ограниченный функционал — большинство онлайн-инструментов не позволяют настраивать диапазон страниц или формат вывода.
Существуют ли альтернативные методы извлечения текста?
Да, некоторые программы чтения или перевода текста имеют базовые функции захвата текста, но они уступают PDF Agile по точности и возможностям.
Когда стоит использовать настольную версию PDF Agile?
Если важна максимальная точность — продвинутые OCR-настройки обеспечат безупречный результат.
Если нужно больше контроля — можно выбирать страницы и формат вывода.
Если важна безопасность — работа офлайн гарантирует защиту данных.
Если требуется редактирование — PDF Agile позволяет редактировать текст прямо в документе.