































PDF Agileはネイティブおよびスキャンファイルの両方から、元の構造・書式・可読性を保持しながらコンテンツを正確に抽出します。長いレポート・契約書・研究論文でも、静的なPDFをクリーンな編集可能テキストに変換できます。
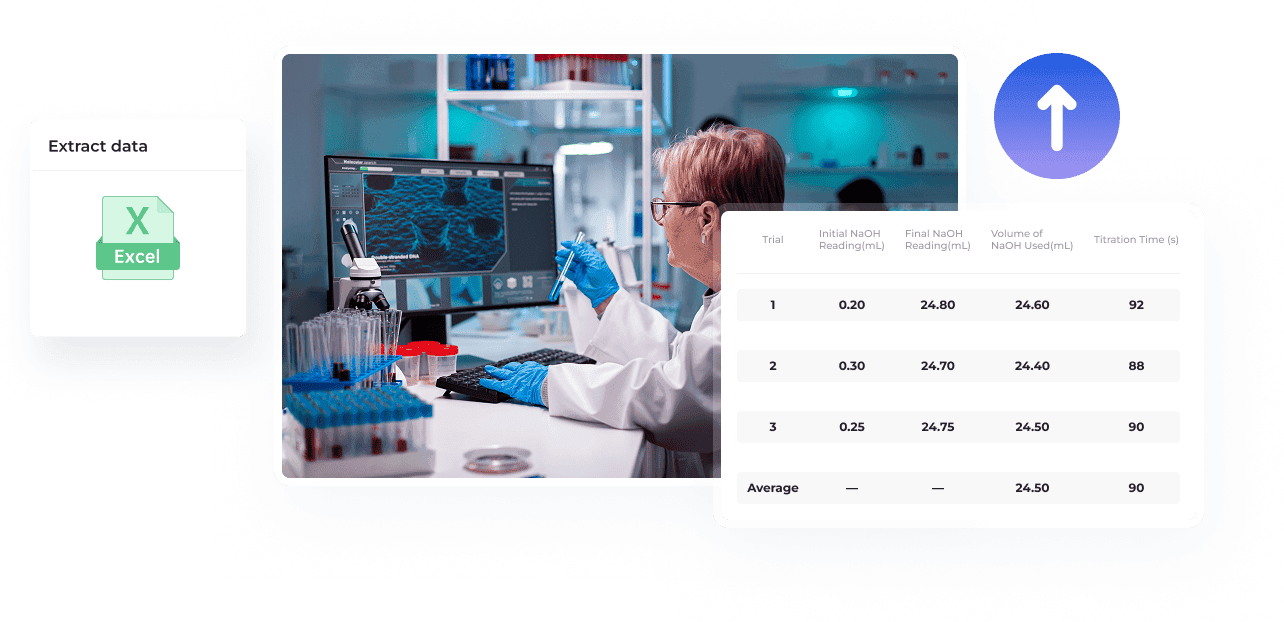
複雑なレイアウトの識別と分離
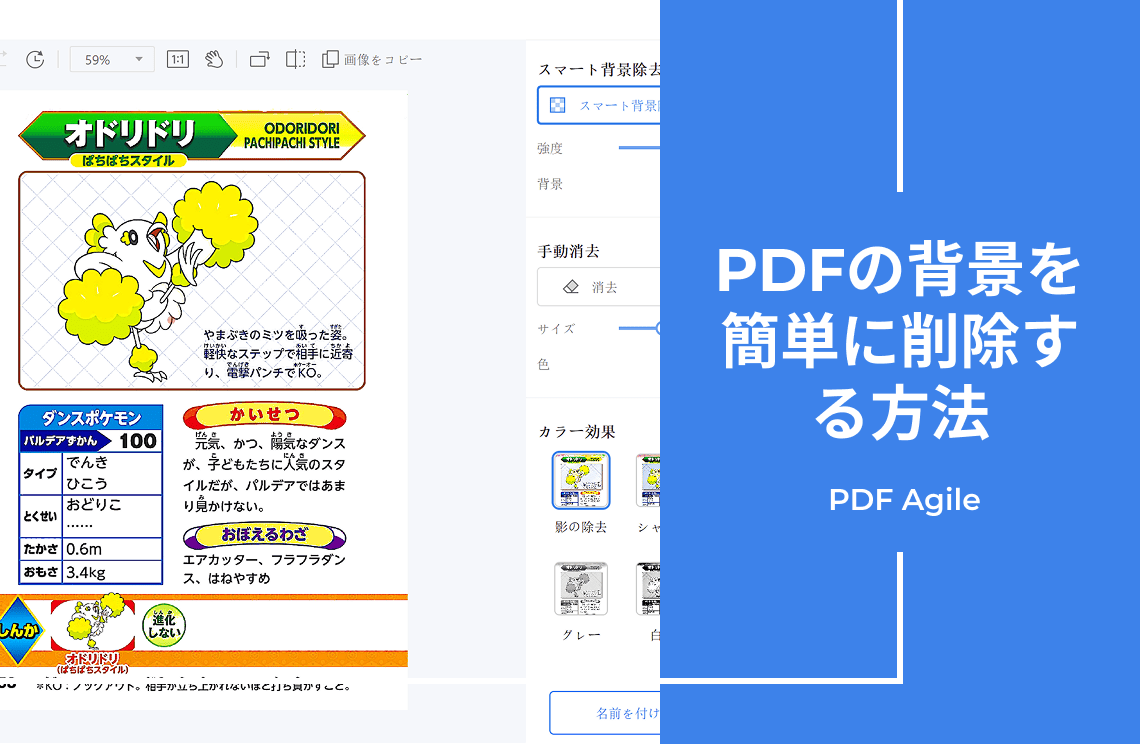
テキスト、画像、表、グラフなど、PDFに含まれるあらゆる要素をインテリジェントに認識・分離し、データを簡単に抽出・再利用・活用できます。
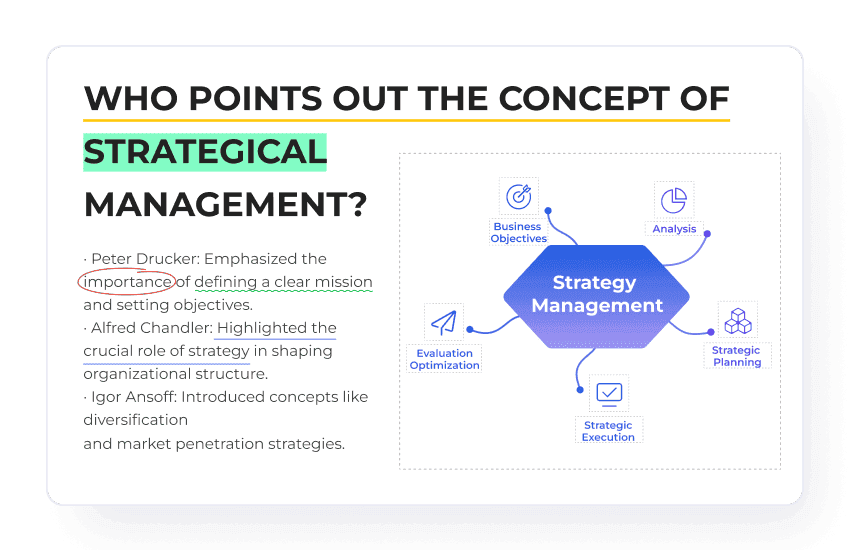
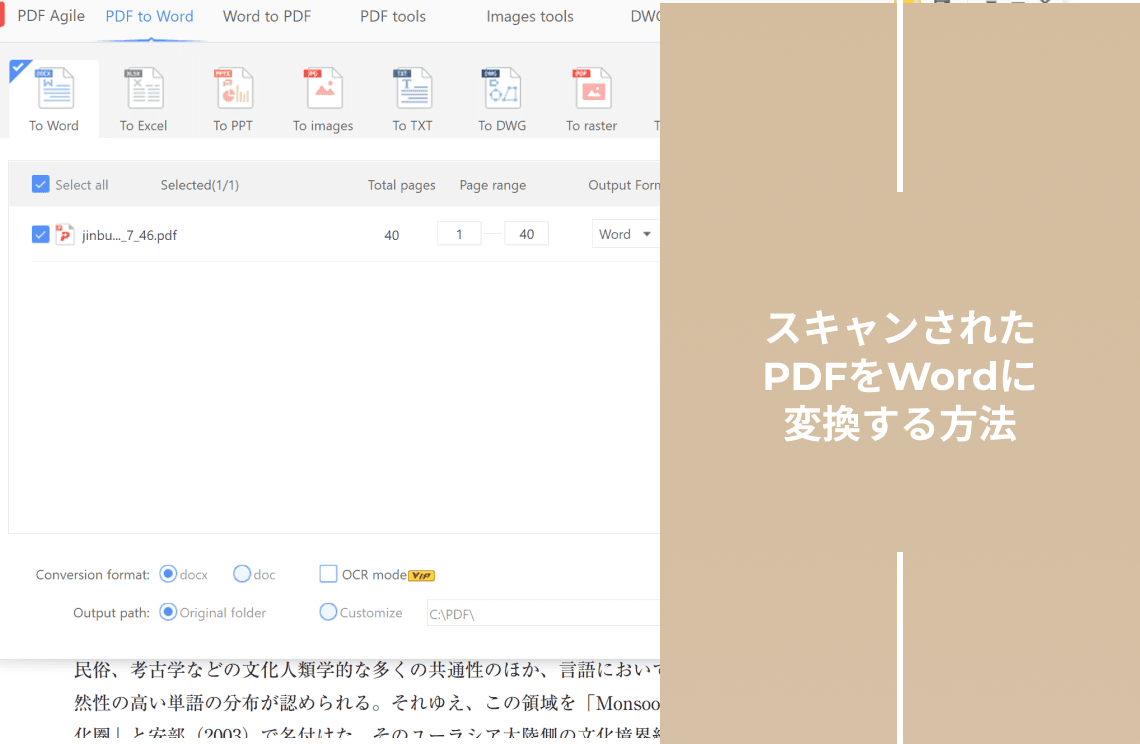
スキャンPDFからテキストを抽出
PDF Agileは高度なOCR(光学文字認識)を使用して、スキャン文書や画像を完全に編集・検索可能なテキストに迅速かつ簡単に変換します。
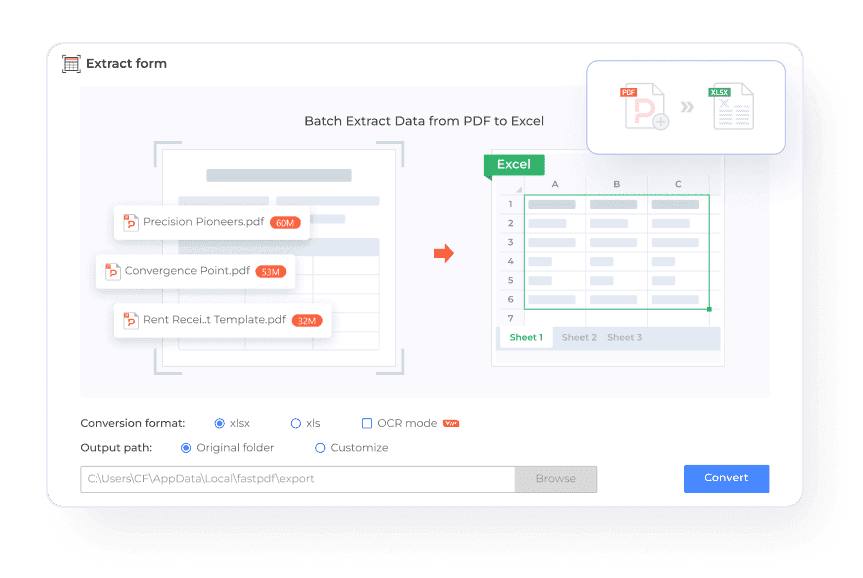
PDFからExcelへのデータ一括抽出
PDF Agileの強力な一括抽出機能で、複数のPDFファイルから一度にデータを取得し、整理されたExcelシートに変換できます。手動作業の時間を大幅に削減しながら、精度と一貫性を確保します。
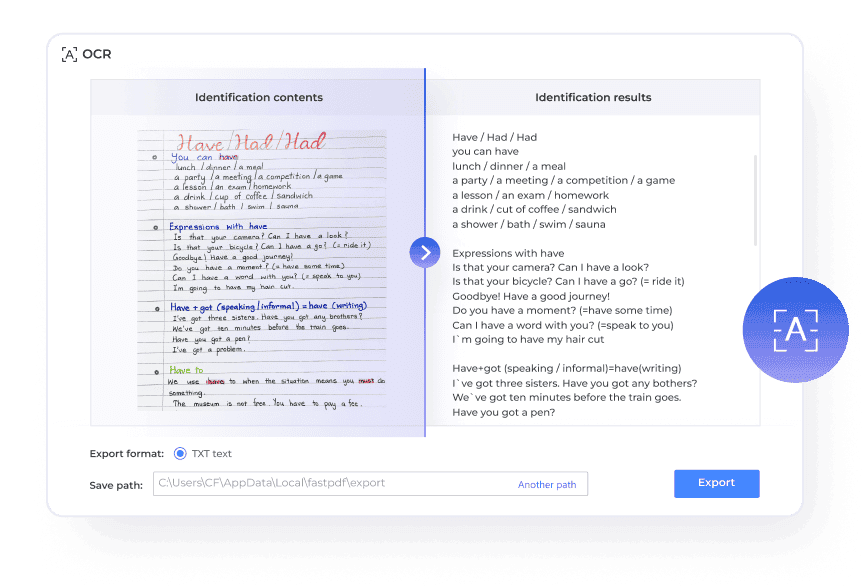
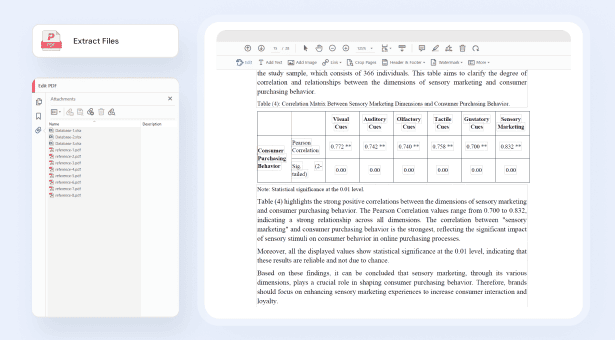
PDFからテキストを抽出

PDFからファイルを抽出
PDF Agileは元のファイル形式の可能性を最大限に引き出し、最も使いやすい形式でコンテンツを復元します。生産性を高め、データ管理をより迅速・クリーン・効率的にします。
PDFをExcelに変換
PDF Agileは詳細なデータ分析を可能にし、情報の編集・更新を容易にし、ExcelやデータベースなどのソフトウェアツールとのExcel連携を実現します。

PDFから画像を抽出
PDF Agileは、さまざまなプロジェクトやプラットフォームでビジュアルコンテンツの柔軟性と使いやすさを向上させます。

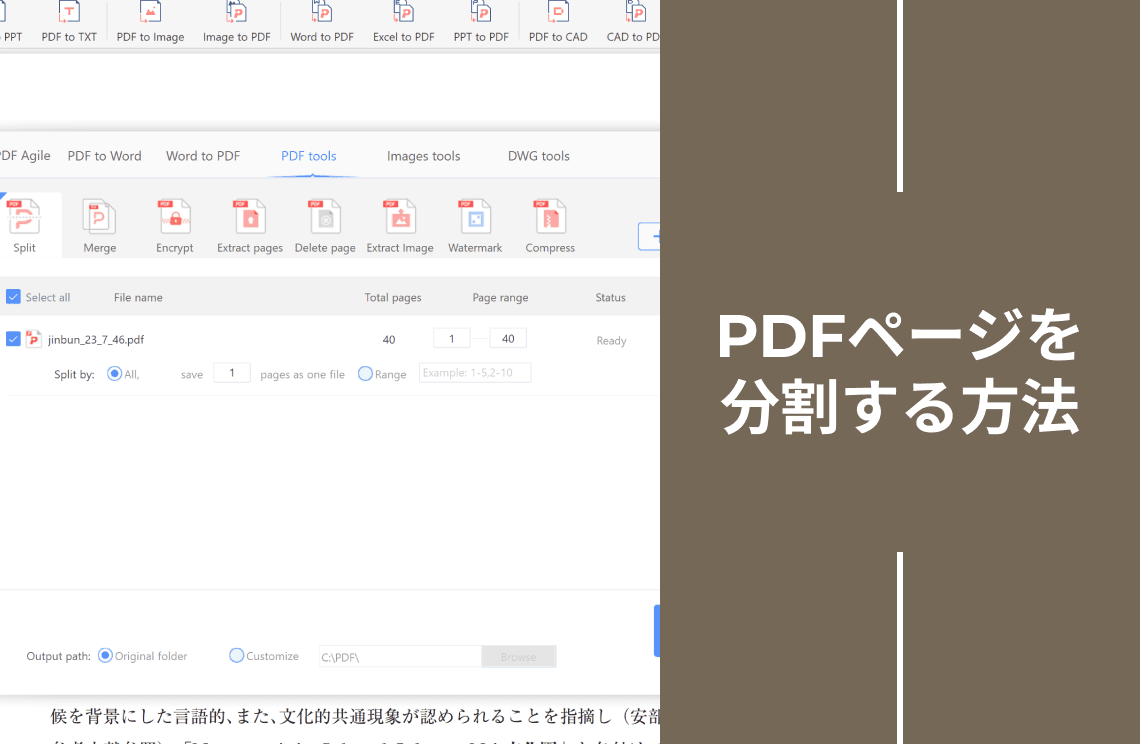
PDFからページを分割
PDF Agileは文書の整理・カスタマイズ・再利用を手間なく実現し、必要なコンテンツに必要なときにアクセスできます。

PDF AgileのPDF抽出機能を活用する6つの実践的な方法

建設
「私は図面・契約書・プロジェクトレポートなど多くのPDF文書を扱います。PDF AgileのPDFデータ抽出機能は革新的で、重要情報を素早く抽出できます。強くお勧めします!」― Chloe Hammer

金融
「金融分野では、精度と効率性が最重要です。PDF AgileのPDFデータ抽出ツールにより、文書処理が効率化され、財務データ、レポート、明細書を簡単に抽出できるようになりました。」 - Ryan Goldstein
学術
「PDF記事、論文、研究論文を頻繁に扱います。PDF Agileのデータ抽出機能により、研究プロセスが効率化されました。手動抽出より分析に集中できます。研究者必携のツールです!」- Dr. Benjamin Booker

法律
「法律分野では、契約書、事件ファイル、法的文書などの大量のPDF文書を扱うことが日常業務です。PDF AgileのPDFデータ抽出機能により、文書管理が革新されました。生産性と精度が大幅に向上しました。」 - Stevens Ethan

人事
「履歴書、雇用契約書、業績評価などの人事文書の管理は時間がかかります。PDF AgileのPDFデータ抽出機能により、このプロセスが簡素化されました。関連情報を迅速かつ正確に抽出できるようになりました。」 - Olivia Miller

ヘルスケア
「医療現場では患者記録・医療レポート・研究論文など多様なPDF文書を扱います。PDF Agileは時間を節約するだけでなく、患者ケアに必要な正確で最新の情報を確保してくれました。」― Dr. Rachel Johnson
建設
「私は図面・契約書・プロジェクトレポートなど多くのPDF文書を扱います。PDF AgileのPDFデータ抽出機能は革新的で、重要情報を素早く抽出できます。強くお勧めします!」― Chloe Hammer
金融
「金融分野では、精度と効率性が最重要です。PDF AgileのPDFデータ抽出ツールにより、文書処理が効率化され、財務データ、レポート、明細書を簡単に抽出できるようになりました。」 - Ryan Goldstein
学術
「PDF記事、論文、研究論文を頻繁に扱います。PDF Agileのデータ抽出機能により、研究プロセスが効率化されました。手動抽出より分析に集中できます。研究者必携のツールです!」- Dr. Benjamin Booker
法律
「法律分野では、契約書、事件ファイル、法的文書などの大量のPDF文書を扱うことが日常業務です。PDF AgileのPDFデータ抽出機能により、文書管理が革新されました。生産性と精度が大幅に向上しました。」 - Stevens Ethan
人事
「履歴書、雇用契約書、業績評価などの人事文書の管理は時間がかかります。PDF AgileのPDFデータ抽出機能により、このプロセスが簡素化されました。関連情報を迅速かつ正確に抽出できるようになりました。」 - Olivia Miller
ヘルスケア
「医療現場では患者記録・医療レポート・研究論文など多様なPDF文書を扱います。PDF Agileは時間を節約するだけでなく、患者ケアに必要な正確で最新の情報を確保してくれました。」― Dr. Rachel Johnson
建設
「私は図面・契約書・プロジェクトレポートなど多くのPDF文書を扱います。PDF AgileのPDFデータ抽出機能は革新的で、重要情報を素早く抽出できます。強くお勧めします!」― Chloe Hammer
金融
「金融分野では、精度と効率性が最重要です。PDF AgileのPDFデータ抽出ツールにより、文書処理が効率化され、財務データ、レポート、明細書を簡単に抽出できるようになりました。」 - Ryan Goldstein
学術
「PDF記事、論文、研究論文を頻繁に扱います。PDF Agileのデータ抽出機能により、研究プロセスが効率化されました。手動抽出より分析に集中できます。研究者必携のツールです!」- Dr. Benjamin Booker
法律
「法律分野では、契約書、事件ファイル、法的文書などの大量のPDF文書を扱うことが日常業務です。PDF AgileのPDFデータ抽出機能により、文書管理が革新されました。生産性と精度が大幅に向上しました。」 - Stevens Ethan
人事
「履歴書、雇用契約書、業績評価などの人事文書の管理は時間がかかります。PDF AgileのPDFデータ抽出機能により、このプロセスが簡素化されました。関連情報を迅速かつ正確に抽出できるようになりました。」 - Olivia Miller
ヘルスケア
「医療現場では患者記録・医療レポート・研究論文など多様なPDF文書を扱います。PDF Agileは時間を節約するだけでなく、患者ケアに必要な正確で最新の情報を確保してくれました。」― Dr. Rachel Johnson
PDF Agileを信頼する何百万人ものユーザーに加わりましょう—今すぐPDFの編集、変換、管理を効率的かつ簡単に。
利用者数






PDFデータ抽出に関するよくある質問
研究論文から特定のデータを抽出したいです。アブストラクトと著者リストだけを取得するにはどうすればいいですか?
請求書がPDF形式です。経理のために請求番号・日付・合計金額を自動的に取り出すことはできますか?
フォームが入力されたPDFがあります。データをスプレッドシートに取り込むには、どうすれば効率的にできますか?
手書き文書のスキャンPDFがあります。テキストを取得するにはどうすればよいですか?
PDFデータ抽出の課題とは何ですか?
PDFデータ抽出のためのベストプラクティスとは?
これまでにないほどPDFワークフローを加速させましょう
あらゆるPDFニーズに対応する完全なPDFソリューション