Extrair texto de documentos PDF tornou-se essencial para fins como investigação, análise de dados e gestão de conteúdos. Uma ferramenta de extração de texto de PDF pode simplificar a recolha e utilização de informação textual desses documentos. Explora a importância da extração de texto de PDFs, as vantagens da tecnologia OCR (Reconhecimento Óptico de Caracteres) e os métodos alternativos para extrair texto sem recorrer ao OCR.
Vamos simplificar o processo apresentando cinco métodos eficazes para extrair texto de qualquer PDF — com OCR para digitalizações baseadas em imagem e sem OCR para documentos digitais. Estas soluções respondem a diferentes necessidades e níveis técnicos, desde cópia manual rápida até ao processamento em lote de múltiplos documentos. Sem jargão complexo nem passos desnecessários, apenas técnicas claras e práticas que funcionam facilmente.
No final, saberás exatamente como fazer isto:
- Converter PDFs digitalizados em texto editável
- Preservar a formatação ao exportar para Word ou Excel
- Extrair texto de vários ficheiros em simultâneo
- Lidar com documentos bloqueados ou protegidos por palavra-passe
- Escolher a ferramenta adequada para cada tarefa específica
Para de reescrever e começa a extrair textos eficientemente. Vamos começar.
A importância de extrair texto de PDFs
A extração de texto de documentos PDF permite um acesso mais fácil à informação contida no documento. Pode melhorar significativamente a eficiência do fluxo de trabalho ao procurar palavras‑chave específicas, analisar o conteúdo ou reutilizar o texto noutros documentos. Assim, os utilizadores poupam tempo e aumentam a produtividade convertendo o texto do PDF para um formato mais editável e pesquisável.
A tecnologia OCR é uma ferramenta poderosa para extrair texto de PDFs digitalizados ou imagens. No entanto, também é possível recorrer a métodos alternativos para obter texto de ficheiros PDF sem a utilizar — úteis quando o OCR não é necessário ou não está disponível. Ao explorares estas técnicas adicionais, alargas o teu conjunto de ferramentas para extração de texto e podes escolher o método mais adequado a cada situação.
Diferentes métodos para extrair texto de PDF com e sem OCR
Extrair texto de PDFs pode ser um desafio comum e frustrante — especialmente em documentos digitalizados, ficheiros bloqueados ou com formatação deficiente. Seja para um estudante a compilar investigação, um profissional a tratar contratos ou alguém que precise de editar um PDF, a impossibilidade de copiar texto representa perda de tempo e esforço.
Trabalhar com PDFs implica, muitas vezes, extrair texto para edição ou reutilização. Quer o teu documento contenha texto pesquisável ou páginas digitalizadas, aqui tens 4 métodos diretos — com e sem tecnologia OCR.
Método 1: Extrair texto com a função OCR do PDF Agile
O OCR (Reconhecimento Óptico de Caracteres) é essencial para PDFs digitalizados ou documentos baseados em imagem. A tecnologia OCR integrada do PDF Agile converte com precisão imagens de texto em conteúdo editável e pesquisável, preservando a formatação. Esta funcionalidade poderosa poupa horas de reescrita manual e funciona de forma notável mesmo com digitalizações de baixa qualidade.
Passos:
1. Abre o PDF Agile e carrega o ficheiro PDF digitalizado.
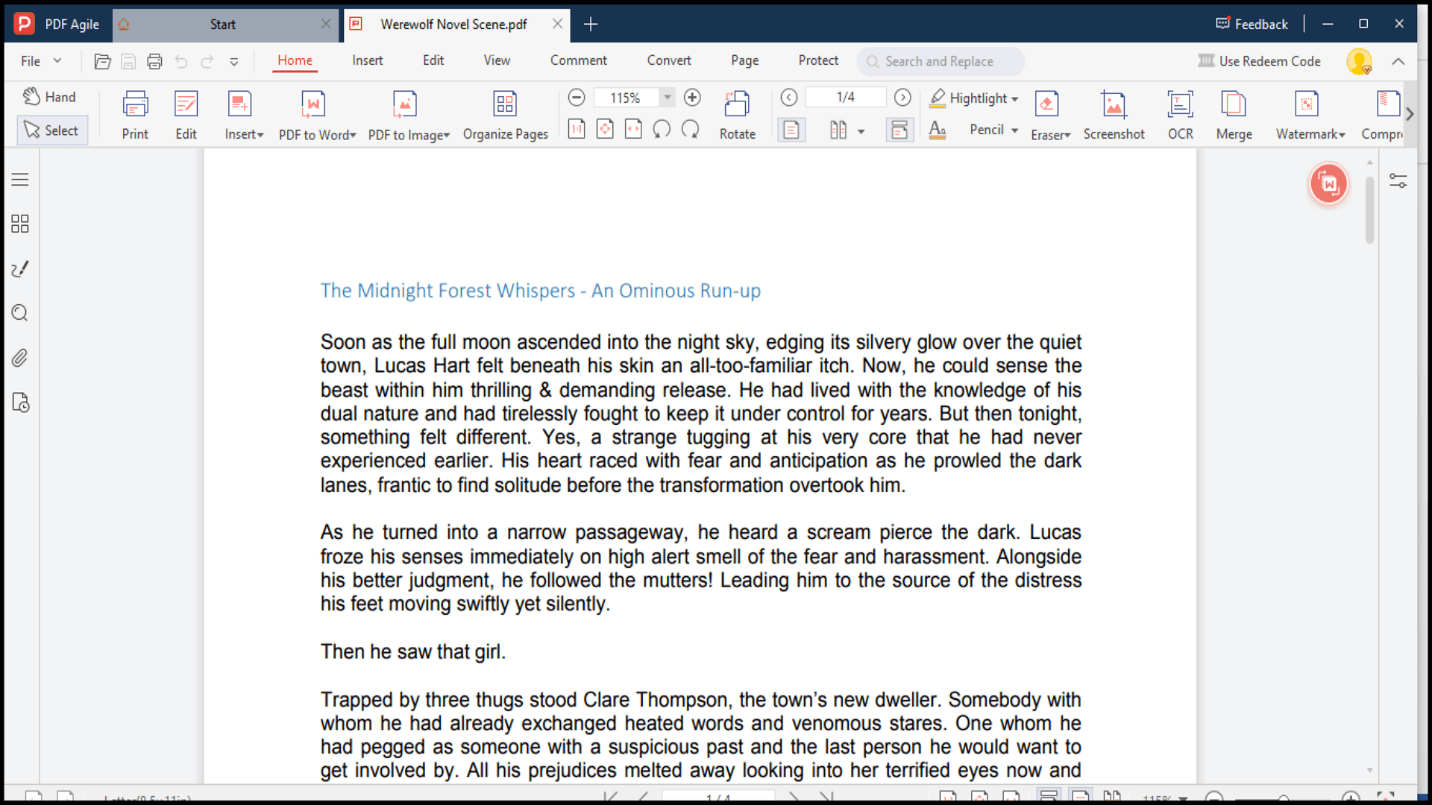
2. Clica no botão “OCR” na barra de ferramentas.

3. O texto do teu documento foi agora extraído.
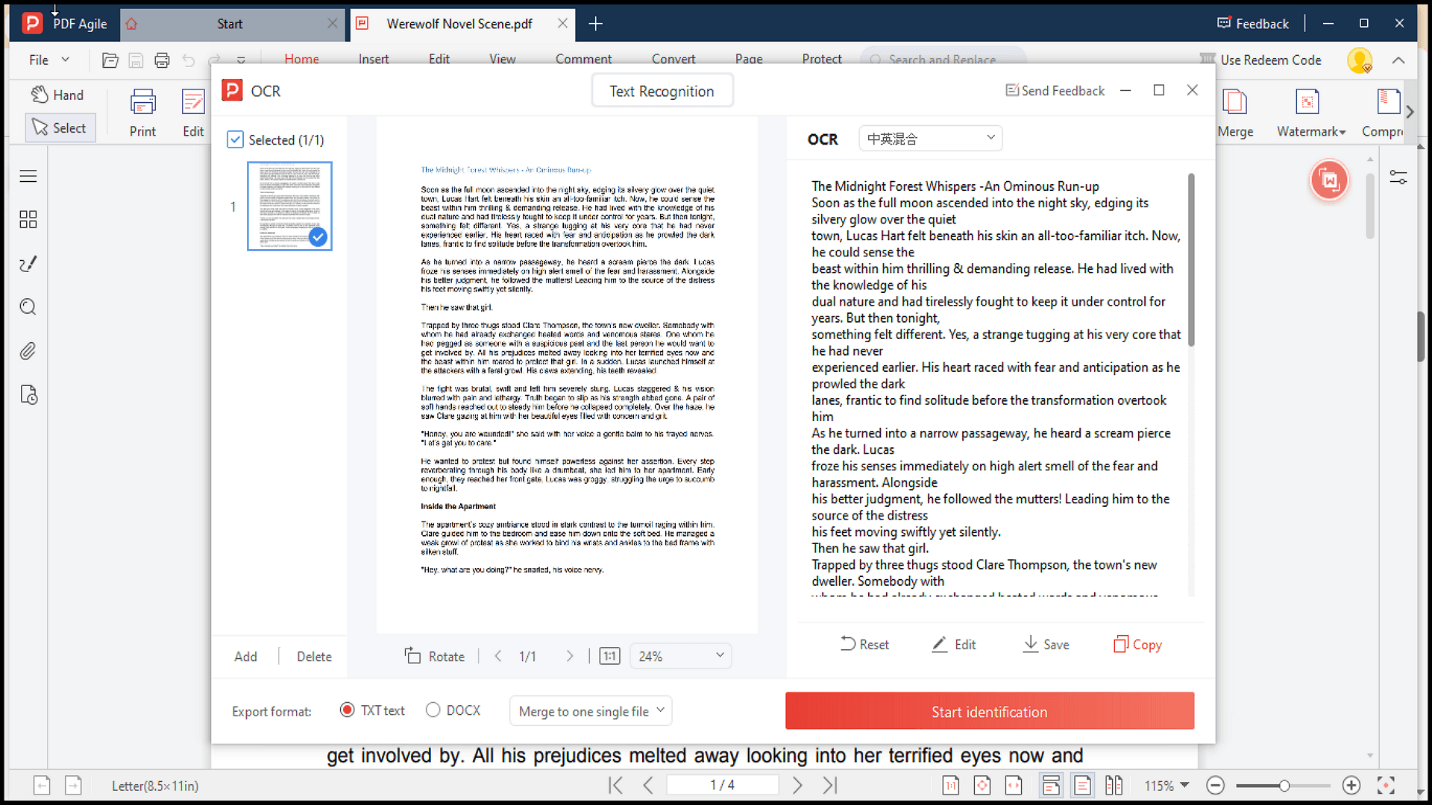
4. Escolhe entre formato de saída TXT ou DOCX.
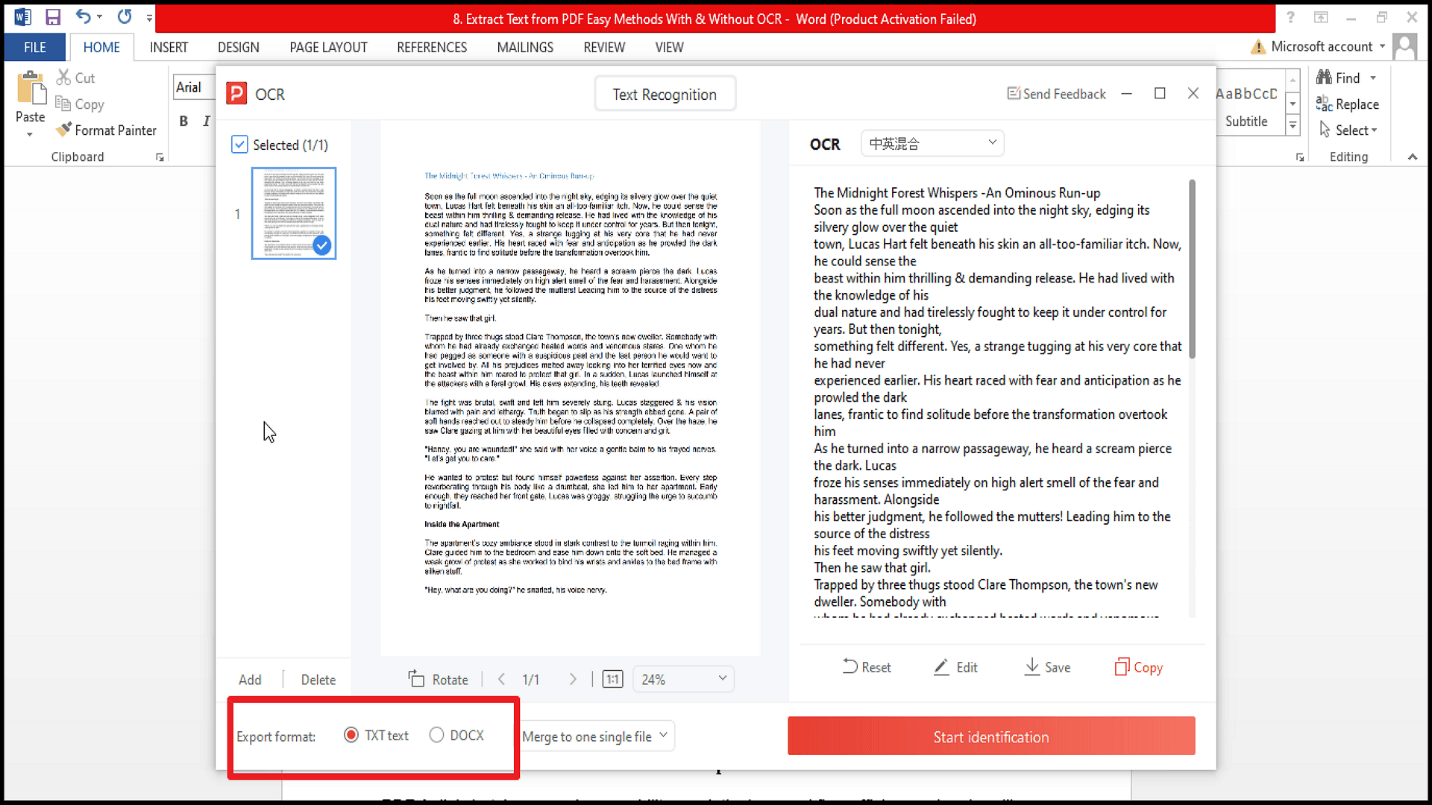
5. Agora podes editar ou guardar o texto.
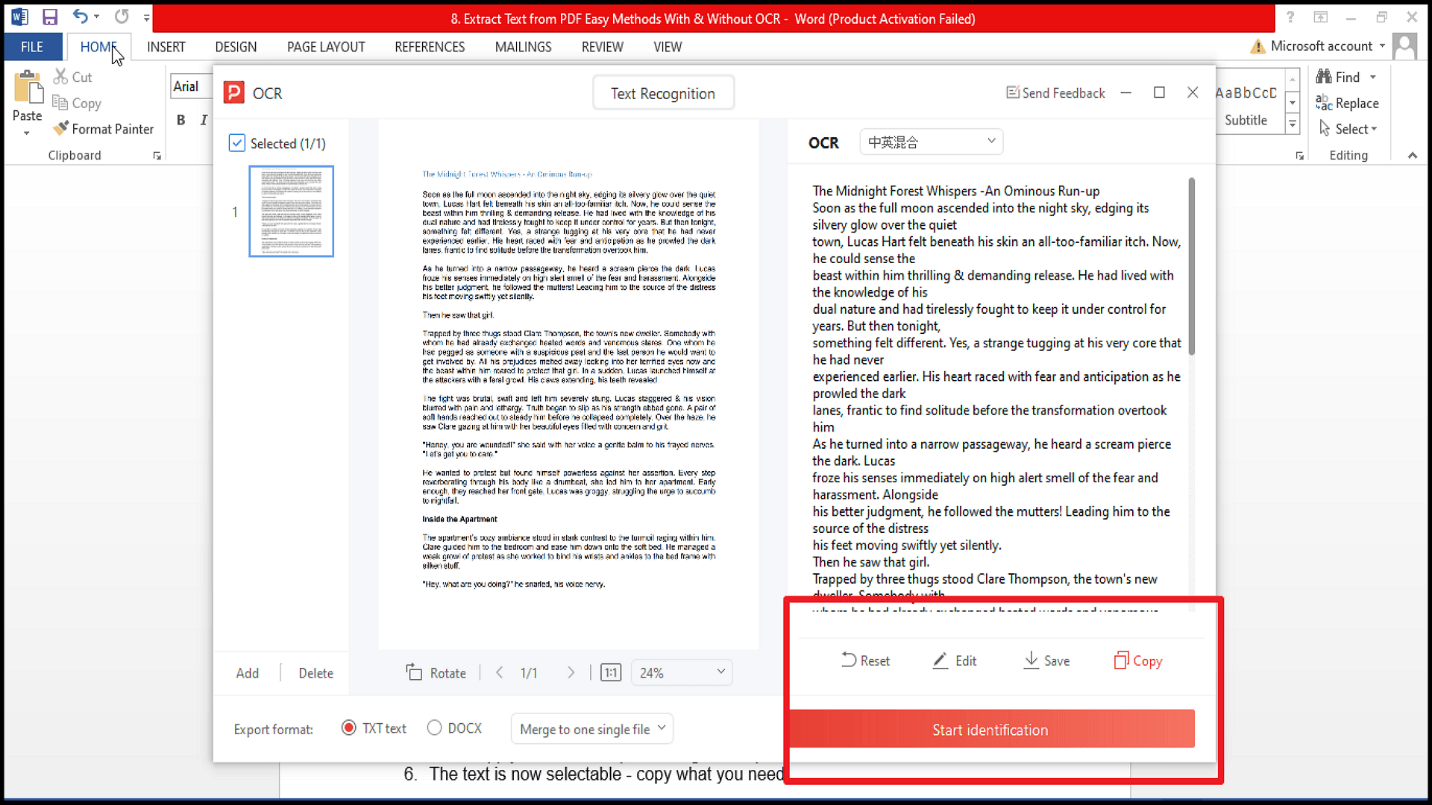
6. O texto já é selecionável — copia o que precisares!
Método 2: Extrair texto com a função exportar do PDF Agile
A função de exportação do PDF Agile oferece a forma mais simples de extrair texto de PDFs normais (baseados em texto). Ao contrário do OCR, que processa imagens, este método converte instantaneamente texto legível em formatos editáveis mantendo a estrutura e formatação básica dos parágrafos.
Passos:
1. Abre a interface do PDF Agile e vai à secção Ficheiro (canto superior esquerdo).
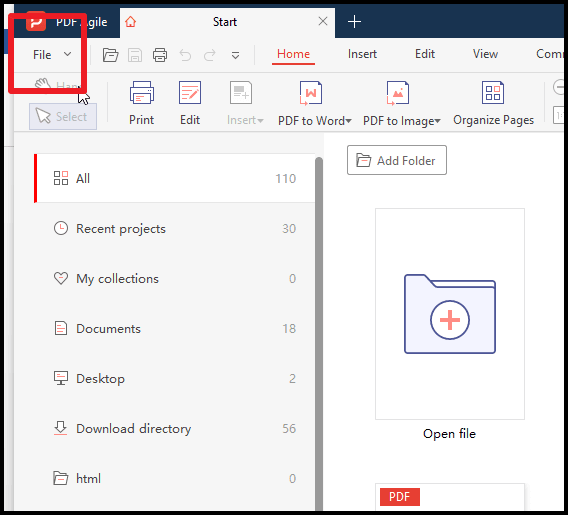
2. Clica no ícone Exportar PDF e seleciona o formato de saída para extrair o texto.
3. Surgirá uma janela de conversão para selecionar o formato desejado.
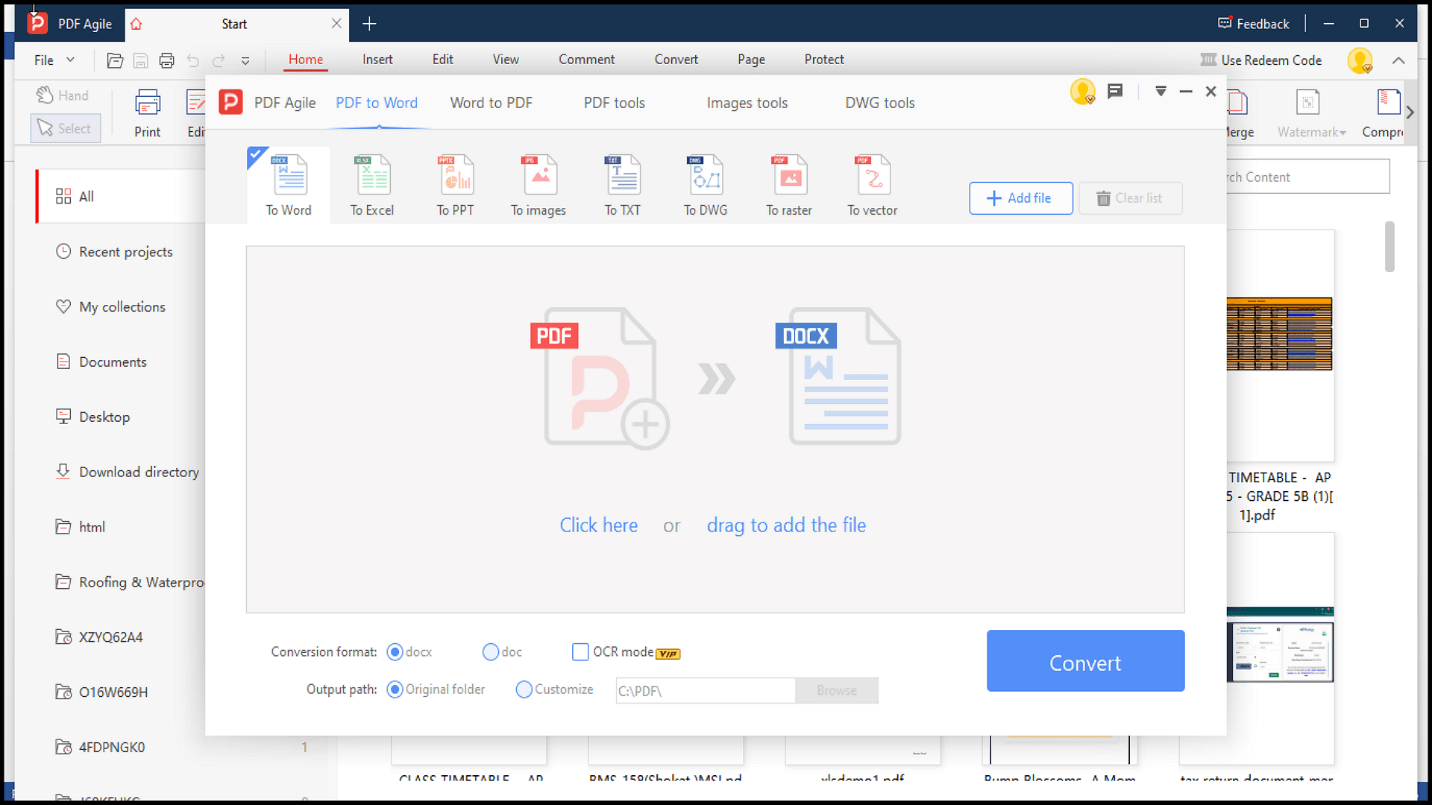
4. Seleciona Adicionar Ficheiro e carrega o PDF.
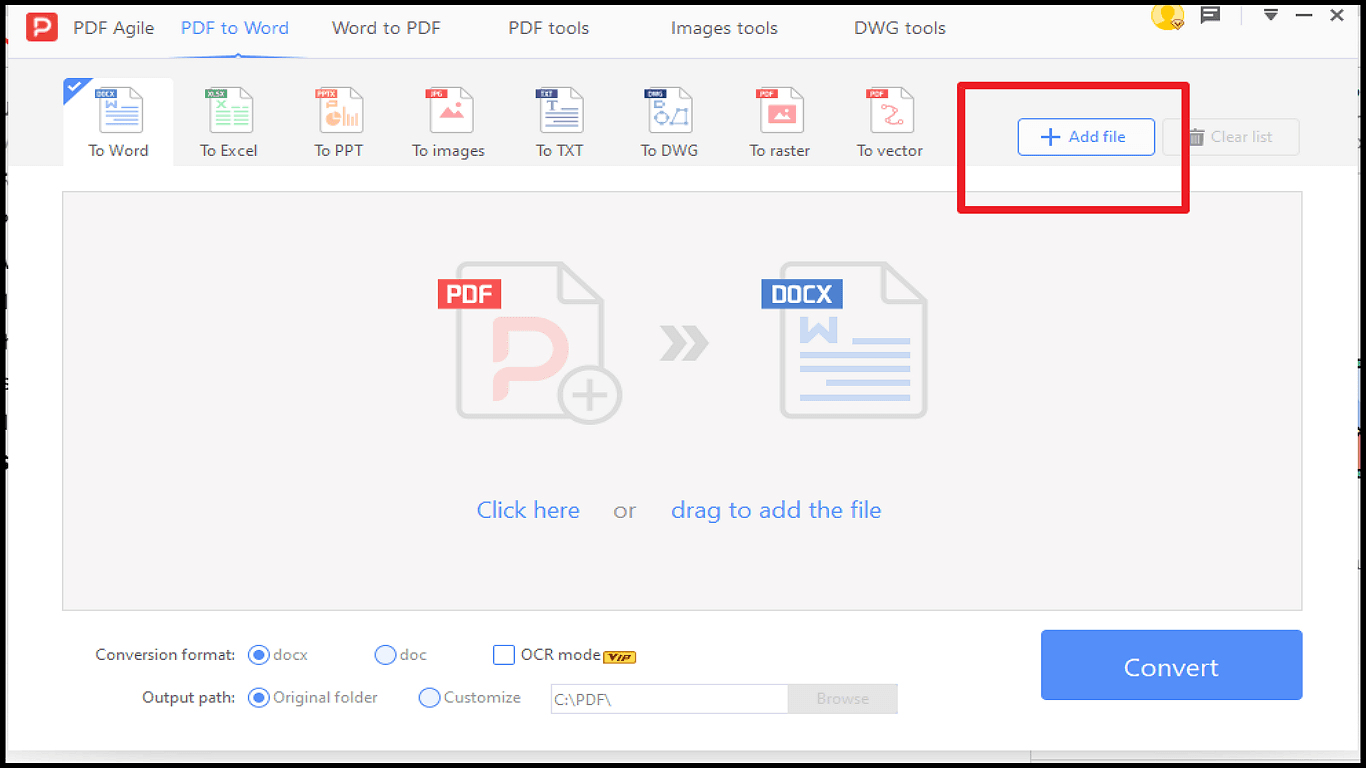
5. Clica em Converter e aguarda alguns segundos.
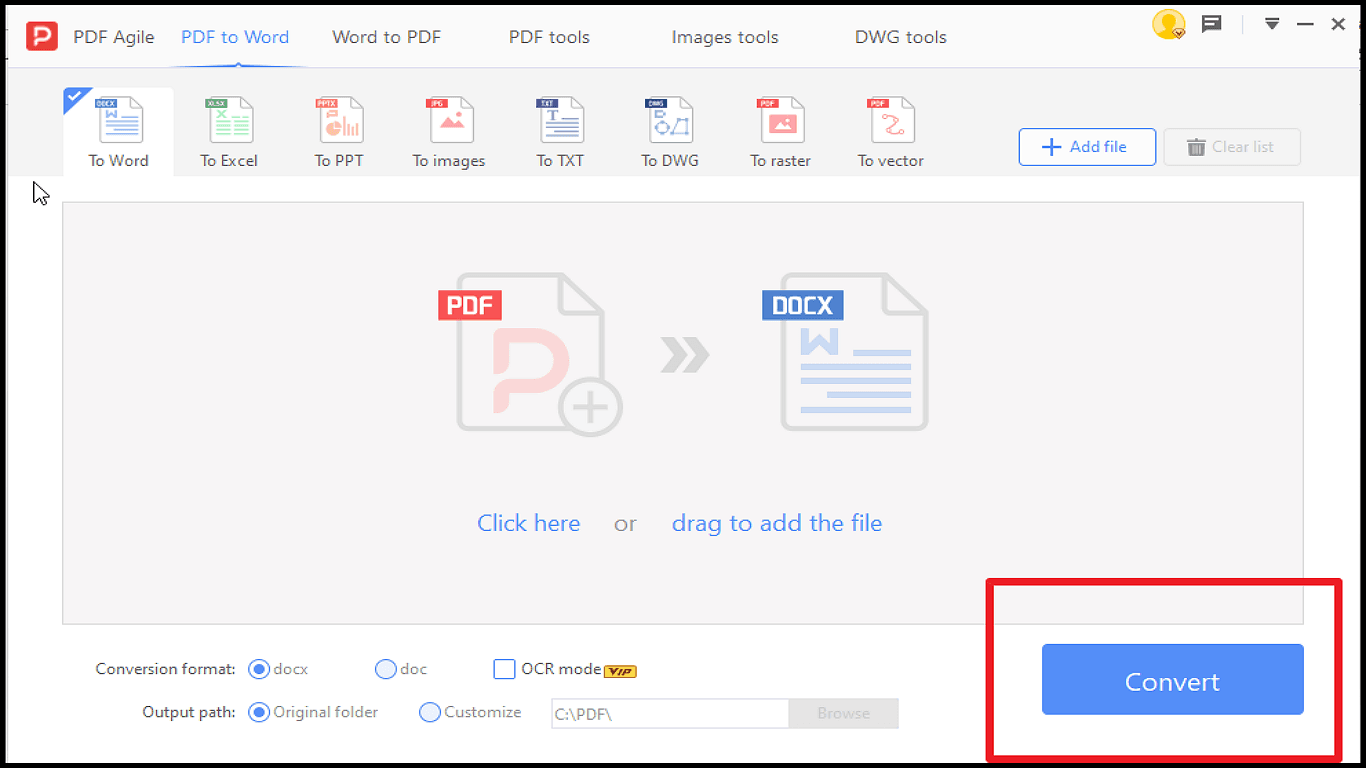
6. O ficheiro está pronto — abre-o no editor do PDF Agile e começa a extrair.
Método 3: Extração manual de texto através do modo de edição
O modo de edição direta do PDF Agile oferece controlo de precisão para capturar rapidamente partes específicas de texto em PDFs normais. Este método é ideal quando precisas apenas de excertos e inclui pré‑visualização em tempo real de formatação. A interface é intuitiva e semelhante a processadores de texto comuns.
Passos:
1. Abre o PDF no PDF Agile e clica em “Editar”.
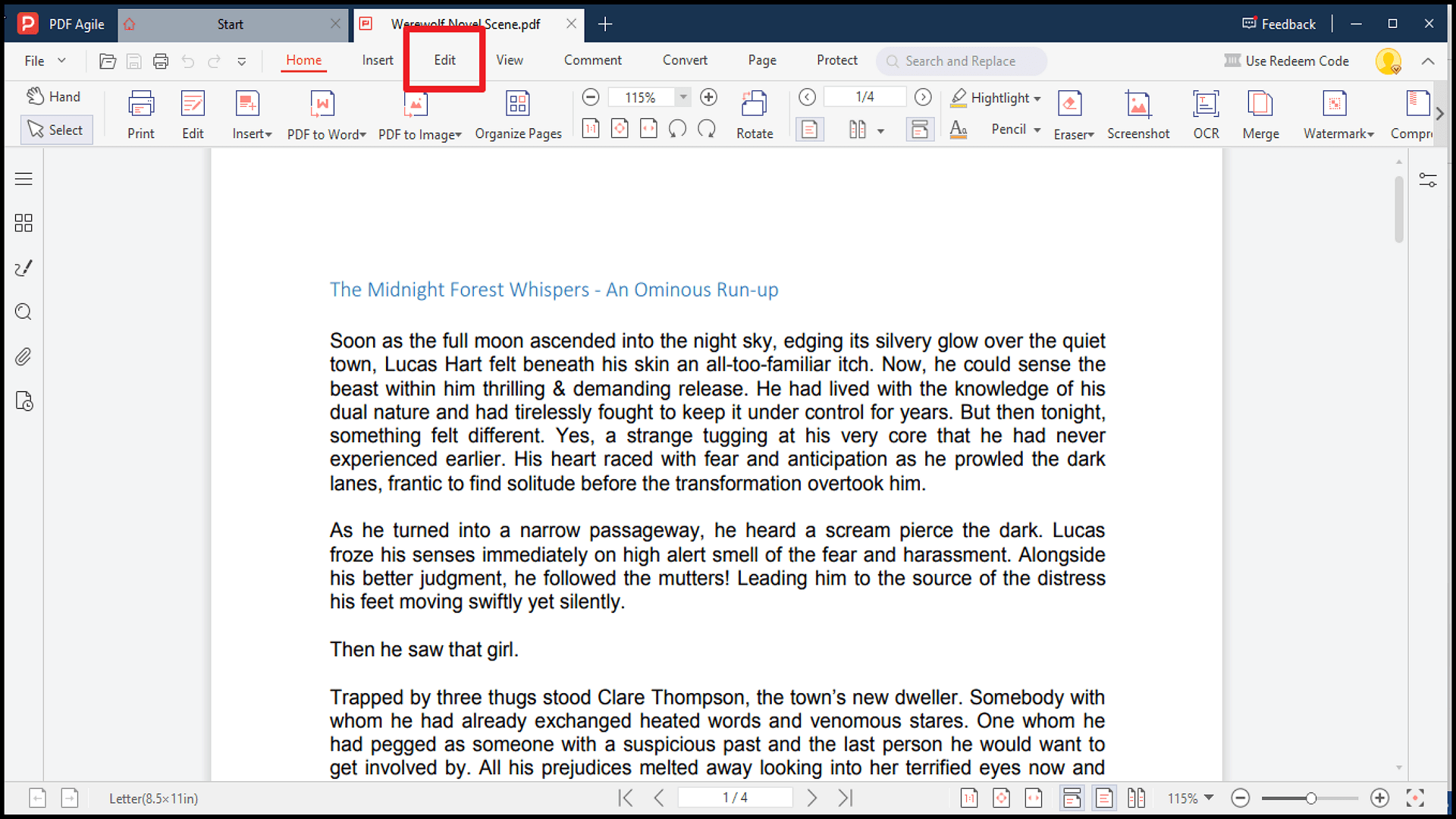
2. Clica com o botão direito no texto desejado e escolhe Copiar ou usa Ctrl+C.

3. Cola o texto numa aplicação externa.
4. Usa a barra de formatação para ajustar tipo/tamanho de letra se necessário.
Método 4: Extrair texto de imagens PDF no Adobe Acrobat
O motor avançado de OCR do Adobe Acrobat trata layouts complexos e digitalizações de baixa resolução com precisão excecional. O reconhecimento de texto assistido por IA suporta mais de 100 idiomas e preserva tabelas, colunas e formatações detalhadas melhor que a maioria das alternativas. Contudo, requer uma subscrição paga.
Passos:
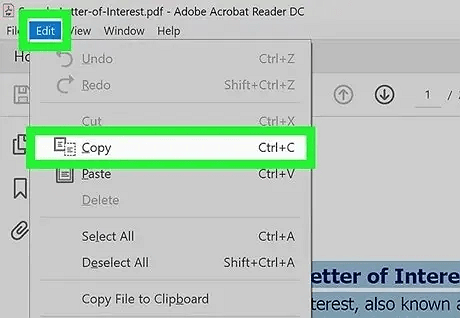
1. Abre o PDF no Adobe Acrobat (não no Reader).
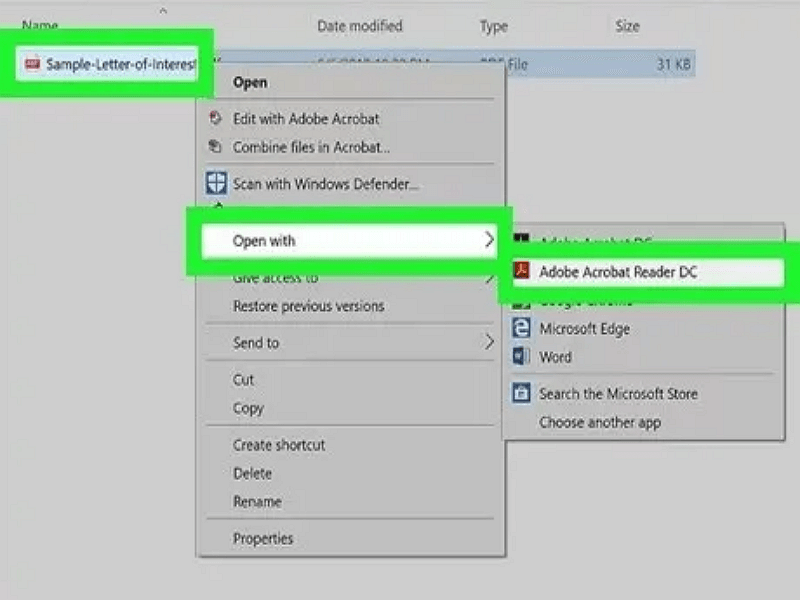
2. Vai a “Editar” e depois clica em “Selecionar Tudo”.
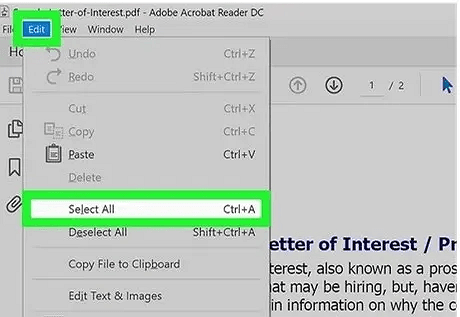
3. Arrasta o cursor sobre o texto para copiar; também podes clicar com o botão direito e escolher Copiar.
Dicas avançadas para extração de texto
- Expressões regulares (Regex): Usa expressões regulares para procurar padrões específicos dentro do texto extraído. Esta técnica avançada permite uma extração mais precisa e eficiente.
- Processamento em lote: Considera o uso de ferramentas de processamento em lote para automatizar a extração quando tens muitos PDFs. Assim poupas tempo e esforço ao lidar com múltiplos ficheiros.
- Extração de metadados: Tenta extrair não só o conteúdo textual, mas também os metadados incorporados (autor, data de criação, etc.), que ajudam a compreender melhor o documento.
- Integração com sistemas de gestão documental: Integra a tua ferramenta de extração com sistemas de gestão documental ou serviços de armazenamento na nuvem. Isso melhora a acessibilidade e organização dos textos extraídos.
Estas dicas avançadas permitem otimizar o teu processo de extração e aumentar a precisão ao gerir textos provenientes de ficheiros PDF.
Perguntas frequentes
Como posso extrair texto de um PDF digitalizado?
Usa ferramentas de OCR (Reconhecimento Óptico de Caracteres) como o PDF Agile para converter imagens digitalizadas em texto editável.
Porque é que o meu PDF não me deixa copiar texto?
- Pode ser um PDF baseado em imagem (usa OCR).
- O ficheiro pode estar protegido por palavra‑passe (desbloqueia‑o com autorização).
- O texto pode não ser selecionável (tenta extração manual ou OCR).
Como extrair texto de vários PDFs de uma só vez?
Usa o Processamento em Lote no PDF Agile:
- Abre a ferramenta de lote.
- Adiciona os PDFs.
- Seleciona “Extrair Texto”.
- Escolhe uma pasta de destino.
Posso copiar texto de um PDF sem instalar software?
Sim! Para PDFs digitais (não digitalizados):
- Abre no Google Drive (botão direito → “Abrir com” → “Google Docs”).
- Ou usa Ctrl+C (se o texto for selecionável).
Como extrair texto de um PDF protegido por palavra‑passe?
Se tiveres a palavra‑passe:
- Abre o PDF no PDF Agile.
- Introduz a palavra‑passe quando for solicitado.
- Exporta ou copia o texto.
Nota: Nunca tentes contornar palavras‑passe sem permissão.
Porque é que o texto extraído fica confuso ou desalinhado?
- PDFs digitalizados: podem ocorrer erros de OCR (tenta melhorar a qualidade da digitalização).
- PDFs digitais: a formatação complexa (tabelas, colunas) pode não copiar corretamente — usa “Exportar para Word” para melhores resultados.
Conclusão
Extrair texto de PDFs — sejam imagens digitalizadas ou ficheiros digitais — não tem de ser complicado. As ferramentas certas permitem converter rapidamente até os PDFs mais difíceis em texto editável e reutilizável.
- Para PDFs digitalizados: As ferramentas OCR do PDF Agile transformam imagens em dados selecionáveis.
- Para PDFs digitais: As funções de exportação integradas e o simples copiar‑colar poupam tempo.
- Para extração em grande volume: O processamento em lote trata vários ficheiros de uma vez — ideal para grandes projetos.
- Para ficheiros bloqueados: A proteção por palavra‑passe não tem de ser obstáculo — existem soluções legítimas (com autorização).
Escolhe sempre o método que melhor se adapta ao tipo de documento e às tuas necessidades. A cópia manual serve para um parágrafo; o OCR automatizado é o melhor aliado para arquivos com páginas digitalizadas.
Agora que conheces estas técnicas, diz adeus à reescrita e dá as boas-vindas a uma extração de texto fluida. Boa edição!