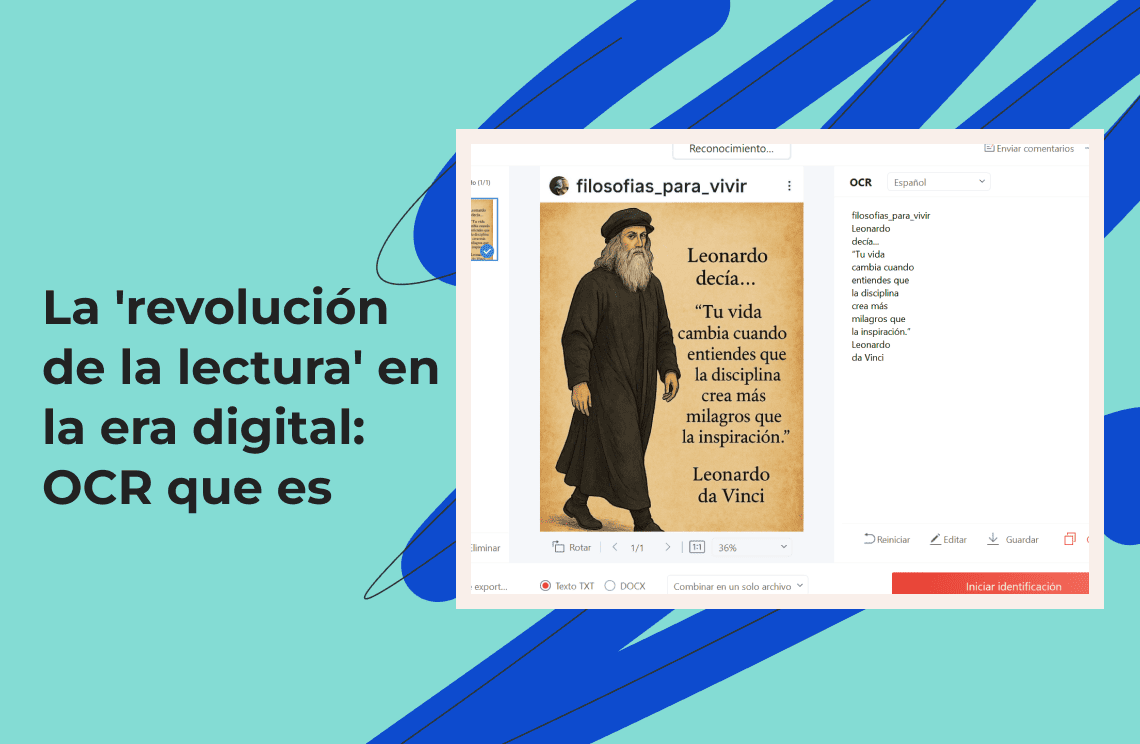
Desde los procesos de apertura de cuentas en Santander y el registro de números de seguimiento en Seur, hasta la realización de trámites en la plataforma Spain Digital o el procesamiento de lotes de contratos con PDF Agile, un "descifrador de texto" invisible está transformando silenciosamente la eficiencia del procesamiento de la información: la tecnología OCR. Esta tecnología está reemplazando gradualmente la tediosa entrada manual de datos, convirtiéndose en un "puente" que conecta la información en papel tradicional con los sistemas digitales modernos. Es también una de las aplicaciones más extendidas del campo de la visión artificial por inteligencia artificial en España. Partiendo de ocr que es, este artículo desglosará cómo esta tecnología derriba las barreras entre el "texto en imágenes" y los "datos digitales", inyectando eficiencia en innumerables sectores, combinando para ello el software local español y las prácticas de la industria.
¿Qué es OCR?
OCR son las siglas de Optical Character Recognition.En términos simples, es la tecnología que permite a la computadora "leer" texto en soportes visuales como imágenes o documentos escaneados, convirtiéndolo de un "formato de imagen" a un "formato de texto editable, buscable y copiable".
El problema central que resuelve es: transformar el "texto escrito en papel/mostrado en una imagen" en texto digital que la computadora pueda procesar directamente.
¿Cómo funciona OCR?
El proceso de convertir a ocr esencialmente simula el proceso humano de "ver el texto → reconocer el texto", pero se desglosa en pasos estandarizados mediante tecnología.
Desde la entrada de la imagen original hasta la salida final del texto editable, la tecnología OCR se divide centralmente en cuatro fases: preprocesamiento de la imagen, localización y segmentación del texto, reconocimiento de caracteres y optimización del postprocesamiento. Cada fase tiene objetivos técnicos y lógica definidos:
Paso 1: Preprocesamiento de la imagen
La imagen original puede tener problemas como desenfoque, inclinación, sombras o ruido, lo que generaría errores en un reconocimiento directo. El objetivo central de este paso es optimizar la calidad de la imagen, haciendo que los contornos del texto sean más nítidos y su posición más uniforme, allanando el camino para el reconocimiento posterior. Se realizan tres tareas clave específicamente:
1)Corrección de la imagen
Problema que resuelve: Fotos tomadas en ángulo, documentos escaneados con ligeras distorsiones.
Lógica técnica: Los algoritmos detectan los bordes del texto en la imagen, calculan el ángulo de inclinación y luego rotan la imagen para alinear el texto horizontalmente. Si la captura es sobre una superficie curva, también aplica corrección de perspectiva para aplanarla.
2)Eliminación de ruido y realce
Problema que resuelve: Imágenes con colores perturbadores, sombras, bajo contraste entre el texto y el fondo.
Lógica técnica: Las técnicas de eliminación de ruido utilizan "algoritmos de filtrado" para eliminar pequeñas manchas o interferencias de píxeles, preservando el contorno del texto. Las técnicas de realce aumentan el contraste entre el texto y el fondo, haciendo los bordes del texto más definidos.
3)Estandarización de especificaciones
Problema que resuelve: Tamaños de texto inconsistentes, baja resolución de la imagen.
Lógica técnica: La imagen se escala proporcionalmente para estandarizar el tamaño del texto, evitando que se pierdan detalles durante el reconocimiento debido a un texto demasiado pequeño.
Paso 2: Localización y segmentación de texto
En la imagen preprocesada, el texto y el fondo ya están separados, pero la computadora aún no sabe "dónde está el texto" o "qué caracteres forman una unidad". El objetivo central de este paso es localizar con precisión las áreas de texto y dividir los párrafos completos en las unidades mínimas que la computadora puede reconocer. Se divide en 2 pasos clave:
1) Localización del área de texto
Objetivo: Seleccionar únicamente las partes con texto de toda la imagen, excluyendo áreas irrelevantes como espacios en blanco, imágenes o logotipos.
Lógica técnica: Actualmente, lo más común es utilizar "algoritmos de detección por aprendizaje profundo" que identifican directamente los bloques de texto en la imagen y devuelven las coordenadas de cada bloque de texto, logrando una localización más precisa y rápida.
2) Segmentación de caracteres
Objetivo: Descomponer los "bloques de texto" localizados en la unidad de reconocimiento más pequeña: letras o números individuales.
Lógica técnica:
- Segmentación horizontal: Primero, separar el bloque de texto por "líneas".
- Segmentación vertical: Luego, separar cada línea según el "espaciado entre caracteres".
- Procesamiento especial: Si hay caracteres unidos o superpuestos, se utilizan algoritmos de "análisis de contornos" para separarlos, garantizando que cada carácter sea independiente.
Paso 3: Reconocimiento de caracteres
Esta es la fase central del OCR: la computadora recibe los caracteres individuales segmentados y, mediante algoritmos, determina "qué carácter es este". Actualmente, el método principal es el reconocimiento mediante aprendizaje profundo, que simula la "red neuronal" del cerebro humano, permitiendo que la computadora "aprenda" las "características" de los caracteres a través de grandes volúmenes de datos. Esto le permite adaptarse a tipografías impresas, escritura manuscrita legible, diferentes fuentes e incluso caracteres ligeramente deformados o borrosos, mejorando enormemente la tasa de reconocimiento. El proceso específico consta de 3 pasos:
1) Entrenar la red neuronal con una enorme cantidad de imágenes de caracteres.
2) Durante el reconocimiento, la red neuronal extrae automáticamente las "características clave" del carácter a identificar.
3) Mediante la comparación de características, devuelve el resultado con la probabilidad más alta.
Paso 4: Postprocesamiento y optimización
Después del tercer paso, la computadora ha generado un texto preliminar, pero aún puede contener algunos errores. El objetivo central de esta fase es corregir estos errores mediante reglas y algoritmos, haciendo que el texto sea más preciso y se ajuste mejor a la lógica del lenguaje. Principalmente realiza 3 tareas:
1) Corrección de errores: Se verifica y corrige basándose en "bases de datos de diccionarios" y "reglas lingüísticas".
2) Validación semántica contextual: Se corrigen errores teniendo en cuenta el contexto.
3) Restauración del formato: Se recupera el formato del documento original, como párrafos, saltos de línea, tablas y puntuación.
Principales tipos de OCR
El OCR puede clasificarse en varios tipos según el escenario de reconocimiento y el método de procesamiento, los cuales se adaptan y optimizan para diferentes necesidades:
1. Clasificación por escenario/soporte de reconocimiento
- OCR de documentos:Reconoce documentos impresos como libros, contratos o escaneos, restaurando su formato y contenido. Tiene la tasa de reconocimiento más alta.
- OCR de documentos de identidad:Se especializa en documentos con formato fijo como pasaportes o licencias comerciales, extrayendo con precisión información estructurada como nombres o números de identificación.
- OCR de recibos y tickets:Reconoce comprobantes financieros como facturas o billetes de tren, extrayendo datos clave como montos o números de impuestos. Se adapta a escenarios con arrugas o inclinación.
- OCR de escritura manuscrita:Admite el reconocimiento de escritura manuscrita legible; la escritura cursiva o muy irregular aún requiere mejoras.
- OCR de escenarios naturales:Reconoce texto en fondos complejos como letreros publicitarios en calles o empaques de productos, enfocándose en resolver el problema de la "dificultad de localización".
- OCR de tablas/fórmulas:Recupera la estructura de filas/columnas de tablas o fórmulas matemáticas, permitiendo la salida en formatos editables como Excel o formatos de fórmula.
2. Clasificación por forma técnica / método de procesamiento
- OCR en línea:Depende del poder computacional en la nube, tiene alta precisión de reconocimiento y admite múltiples escenarios. Es adecuado para el procesamiento por lotes.
- OCR sin conexión:El reconocimiento se completa localmente en el dispositivo, no requiere conexión a Internet y ofrece seguridad de los datos. Ideal para escenarios que manejan información confidencial.
- OCR con aprendizaje profundo:Tecnología principal actualmente. Ofrece alta adaptabilidad y tasas de reconocimiento superiores.
- OCR tradicional basado en plantillas: Básicamente obsoleto, solo aplicable a escenarios simples con fuentes impresas.
Beneficios de usar OCR
El valor central del OCR gira en torno a "reducir costos, mejorar la eficiencia y liberar el valor de la información", manifestándose concretamente en cinco aspectos principales:
1. Eficiencia multiplicada: Reemplaza la entrada manual, ahorrando mucho tiempo.
La ventaja más directa del OCR es que su eficiencia en la extracción de texto y la entrada de información supera con creces a la del trabajo manual, y esta ventaja es más evidente en escenarios complejos.
Mejora de eficiencia en una sola tarea:
- Una página A4 con texto impreso: mecanografiarla manualmente toma 10-15 minutos; el reconocimiento por OCR + una verificación simple toma menos de 30 segundos, mejorando la eficiencia 20-30 veces.
- La información clave de una factura: introducirla manualmente toma 2-3 minutos; la extracción automática por OCR toma solo 2-3 segundos, mejorando la eficiencia 40-60 veces.
La ventaja es más prominente en el procesamiento por lotes:
- Reembolsos mensuales de finanzas empresariales con 1000 facturas: la entrada manual requeriría 1000 × 3 min = 50 horas; el procesamiento por lotes con OCR + verificación manual requiere solo 2-3 horas, ahorrando más del 95% del tiempo.
- Digitalización de 10,000 páginas de libros en papel en una biblioteca: la mecanografía manual llevaría meses; el escaneo con OCR + corrección lleva solo días, acortando significativamente el ciclo de digitalización.
2. Reducción de costos: Disminuye la inversión en mano de obra y evita pérdidas por errores humanos.
A largo plazo, el OCR puede reducir los costos laborales y por errores de las empresas al reemplazar la entrada manual de datos, siendo especialmente adecuado para escenarios con "entrada de información frecuente y voluminosa".
Reducción de costos laborales:
En departamentos tradicionales como archivo o finanzas, se necesitaban varios empleados dedicados a la entrada de documentos en papel y verificación de recibos. Con la introducción del OCR, 1-2 personas pueden completar el trabajo que antes realizaban 5-10, reduciendo directamente los costos de contratación y gestión de personal.
Evita pérdidas por errores:
La tasa de error de la entrada manual suele ser del 3%-5%, lo que puede tener consecuencias graves. La tasa de error del OCR en texto impreso es inferior al 0.1%, y es aún menor para información estructurada, evitando casi por completo "errores básicos de entrada" y reduciendo los costos de tiempo y las pérdidas económicas asociadas a las correcciones posteriores.
3. Activación de la información: Convierte el "texto en imagen" en "datos utilizables", liberando su valor.
El texto en imágenes, documentos escaneados o en papel es esencialmente "información inerte": no se puede editar, buscar ni procesar en masa. El OCR lo transforma en "datos vivos", dotando de operatividad a la información, con las siguientes ventajas:
- Editabilidad: El texto en escaneos e imágenes, después del OCR, puede generar formatos como Word o Excel, permitiendo modificaciones, ajustes de formato y reelaboración.
- Capacidad de Búsqueda:Los documentos digitalizados permiten, mediante la extracción de palabras clave por OCR, crear índices para localizar rápidamente el documento objetivo introduciendo dichas palabras clave.
- Procesamiento por Lotes: El texto digital resultante del OCR se puede importar a Excel, bases de datos o sistemas operativos para realizar estadísticas y análisis por lotes.
4. Fuerte adaptabilidad: Cubre múltiples escenarios, satisfaciendo flexiblemente diferentes necesidades.
Tras años de iteración tecnológica, el OCR puede ahora satisfacer las necesidades personalizadas de diferentes industrias y usuarios:
- Se adapta a diferentes soportes: Admite el reconocimiento de texto en fotos, escaneos, PDF, capturas de pantalla, imágenes de escenarios urbanos, libros antiguos, etc.
- Se adapta a diferentes tipos de texto:Admite texto impreso, escritura manuscrita legible, múltiples idiomas, fuentes artísticas y símbolos especiales.
- Se adapta a diferentes entornos de uso:Admite reconocimiento rápido en línea, reconocimiento sin conexión para privacidad, reconocimiento inmediato en dispositivos móviles y reconocimiento por lotes en entornos empresariales.
- Valor central: Ya sea para extraer texto de capturas de pantalla personales, procesar documentos por lotes en empresas, o escenarios de alto requerimiento en administración pública o finanzas, siempre existe una solución OCR correspondiente, con una flexibilidad extrema.
5. Mejora de la experiencia: Simplifica los flujos de operación, reduce las barreras de uso.
Tanto para usuarios individuales como empresariales, el OCR simplifica flujos de operación originalmente complejos, reduce las barreras de uso y permite que diferentes grupos y roles puedan utilizarlo rápidamente, mejorando la experiencia de uso y la eficiencia del flujo de trabajo:
- Usuarios individuales:Sin necesidad de habilidades profesionales, después de tomar una foto o una captura de pantalla con el móvil, pueden extraer texto con un solo clic, admitiendo copiar, compartir o traducir directamente, con una barrera de uso cero.
- Usuarios empresariales / gubernamentales:Los trámites son más sencillos. Los ciudadanos pueden subir fotos de sus documentos para que la información se ingrese automáticamente en trámites administrativos, sin llenar formularios largos manualmente. Los empleados pueden tomar fotos de sus facturas para generar automáticamente formularios de reembolso, sin necesidad de introducir los datos manualmente.
Usos comunes de OCR
Al vivir, trabajar o estudiar en España, es común encontrarse con la necesidad de digitalizar textos en español a partir de documentos escaneados o imágenes. A continuación, se presenta una selección de 10 herramientas de OCR de calidad, adaptadas al español, cubriendo tanto necesidades cotidianas como profesionales.
5 herramientas de ocr gratis online
Las herramientas de OCR en línea no requieren descarga ni instalación, se operan directamente a través del navegador. Son ideales para uso ocasional y tareas ligeras diarias. Todas ellas identifican con precisión los caracteres especiales del español y equilibran la protección de la privacidad con la conveniencia.
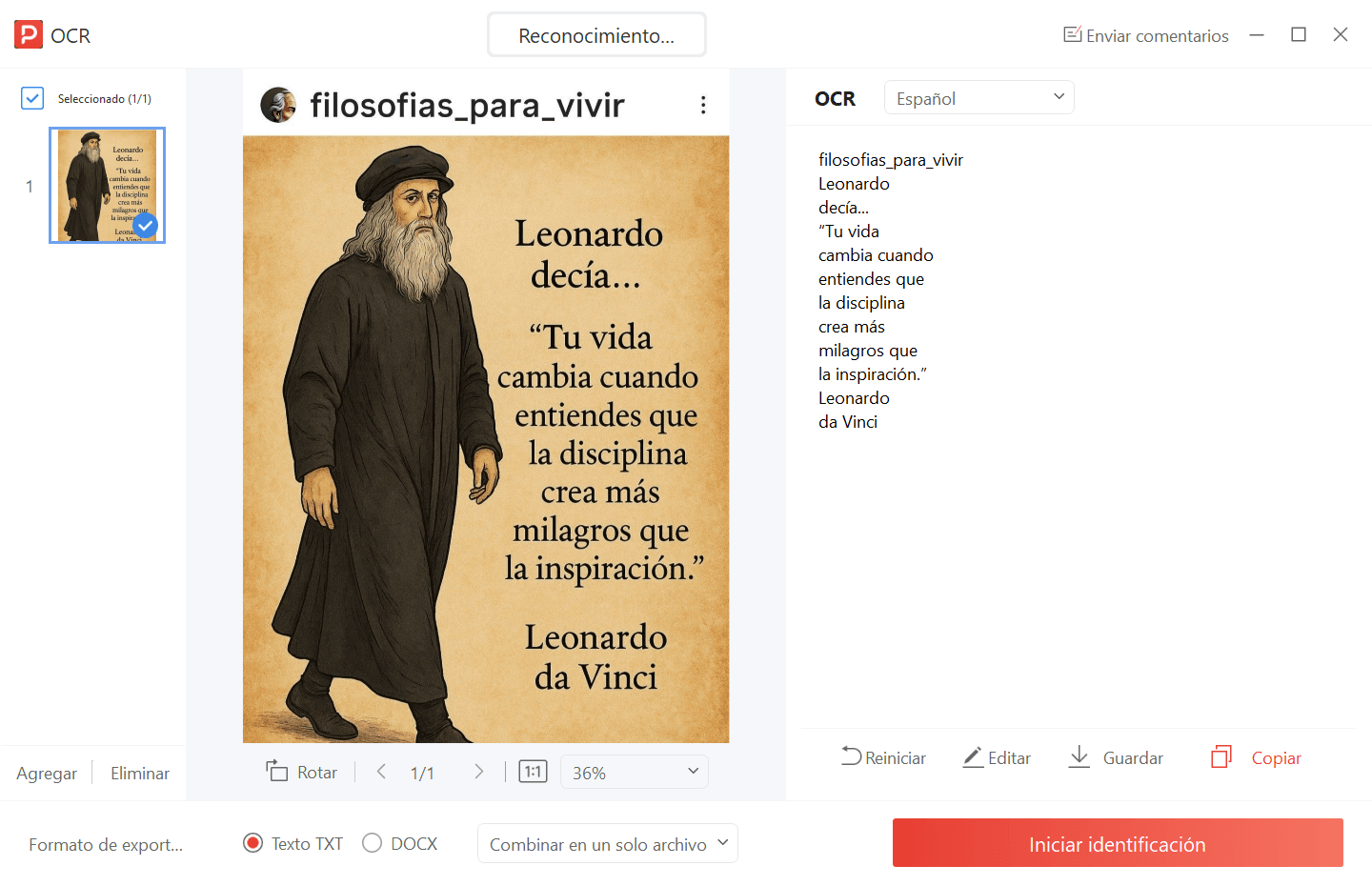
1. PDF Agileversión online
Ventaja principal:Incorpora un potente motor de OCR de texto completo capaz de extraer texto de documentos escaneados o imágenes. Admite el reconocimiento de 20 idiomas y permite la conversión bidireccional en línea entre PDF y múltiples formatos comunes, incluyendo Word, Excel, PowerPoint, TXT, JPG, PNG y formatos CAD como DWG.Durante el proceso de Extraer texto de PDF, conserva eficazmente las fuentes, el diseño y el formato del archivo original, evitando la necesidad de un re-maquetado. Se adapta a la necesidad de convertir documentos entre múltiples formatos en entornos de oficina, haciendo que los PDF escaneados, originalmente no editables, sean buscables y editables.
Caso de uso ideal:Ideal para la digitalización de recibos en español en pequeñas empresas españolas, texto de carteles, y para extraer información de señales o folletos a nivel personal.
Punto adicional: No requiere registro; el procesamiento comienza inmediatamente después de subir el archivo.
 2. i2OCR
2. i2OCR
Ventaja principal:Completamente gratuito, sin requisitos de registro y con una excelente adaptación al reconocimiento del español. Admite formatos como PDF escaneado, JPG, PNG, etc., y genera formatos editables como texto plano, Word, HTML o PDF.。
Caso de uso ideal:Ideal para usuarios en España que procesen menús diarios, folletos o documentos simples. No tiene límites de uso ni de número de archivos. Su operación requiere solo dos pasos: seleccionar "español" y subir el archivo, siendo ideal para principiantes.
Punto adicional: Los archivos se eliminan automáticamente después del procesamiento, sin preocupaciones por filtraciones de datos.
3. 2OCR
Ventaja principal: Gratuito y sin barreras de uso. Admite español y otros idiomas minoritarios de España como el catalán. Compatible con múltiples formatos como PDF, DOC, JPG, etc. Tras el reconocimiento, genera un PDF buscable que coincide con el diseño original, facilitando la verificación.
Caso de uso ideal: Digitalización de facturas en español y documentos en papel. Permite copiar directamente el resultado reconocido en el navegador sin necesidad de descargarlo, ahorrando tiempo.
Punto adicional: No requiere proporcionar información personal, evitando tediosos procesos de registro.
4. Easy Screen OCR
Ventaja principal: Utiliza el motor de aprendizaje automático de Google, logrando una alta precisión en el reconocimiento del español. Admite la subida y procesamiento por lotes de hasta 5 imágenes. Los resultados se pueden comprimir en un archivo TXT para descargar y es compatible con atajos de teclado.
Caso de uso ideal: Entornos de oficina multinacionales y extracción de texto multilingüe. Adecuado para procesar rápidamente múltiples recibos o imágenes de notas en español.
Punto adicional: Las imágenes subidas se eliminan automáticamente después de 30 minutos, equilibrando conveniencia y seguridad.
5. OCR Free
Ventaja principal: Admite más de 100 formatos de archivo, permitiendo subirlos sin necesidad de conversión previa. Tras reconocer el texto en español, permite editarlo directamente en línea y exportarlo en formato TXT.
Ventaja principal: Admite más de 100 formatos de archivo, permitiendo subirlos sin necesidad de conversión previa. Tras reconocer el texto en español, permite editarlo directamente en línea y exportarlo en formato TXT.
Punto adicional: Admite la subida de archivos arrastrándolos, con una interfaz sencilla que no requiere conocimientos técnicos para utilizarla.
5 herramientas de OCR profesionales que requieren descarga
Las herramientas que requieren descarga ofrecen funciones más completas, incluyendo procesamiento por lotes, conservación del diseño de documentos complejos y uso sin conexión. Son ideales para entornos empresariales y el procesamiento profesional de documentos, con mayor precisión en el reconocimiento del español y mejores funcionalidades.
1. PDF Agile
Ventaja principal:Esta herramienta integral para PDF incluye un motor OCR de alto rendimiento que admite explícitamente el español y otros 19 idiomas. Convierte documentos escaneados en español o PDF basados en imágenes en texto editable, conservando completamente el formato original. Para documentos confidenciales, permite establecer contraseñas para prevenir accesos no autorizados, además de ocultar o eliminar permanentemente texto e imágenes confidenciales. Adicionalmente, ofrece tres métodos de firma electrónica, agilizando la firma de contratos y otros documentos. Se adapta a sectores con altos requisitos de confidencialidad documental, como finanzas o derecho.
Caso de uso ideal:Oficinistas españoles y pequeñas empresas que procesan contratos e informes en español. Integra funciones de edición, conversión y anotación de PDF. Tras la Extracción de texto mediante OCR, este se puede modificar directamente sin necesidad de software adicional.
Punto adicional:Compatible con Windows, interfaz intuitiva y fácil de usar, ideal para principiantes.

2. UPDF
Ventaja principal:Alta precisión en el reconocimiento de español, conserva los detalles de formato del documento. Sus herramientas de IA integradas pueden resumir, explicar o traducir texto en español. Admite la exportación a múltiples formatos.
Caso de uso ideal:Ideal para el procesamiento de documentos comerciales y materiales académicos en español en entornos empresariales, y para documentos personales en español con estructuras complejas. Admite el uso compartido en la nube y el cifrado de documentos, combinando utilidad y seguridad.
Punto adicional:Sincronización multidispositivo, ideal para el trabajo móvil. Reconocimiento impecable de caracteres especiales en español.
3. Umi - OCR
Ventaja principal:De código abierto y gratuita. Funciona sin conexión, evitando filtraciones de datos confidenciales. Reconoce con precisión los acentos y estructuras especiales del español. Admite carga por lotes y permite definir áreas de reconocimiento personalizadas.
Caso de uso ideal:Para usuarios individuales que procesan notas, recibos o folletos en español. Ideal para usuarios en España que manejan documentos privados como historiales médicos o contratos personales. Los resultados se pueden exportar a TXT o Word.
Punto adicional: Compatible con Windows, instalación sencilla y sin publicidad.
4. ABBYY FineReader
Ventaja principal:Herramienta de OCR profesional reconocida internacionalmente. Líder en precisión para texto impreso en español. Admite el procesamiento por lotes de documentos largos en español, conservando diseños complejos. También reconoce escritura manuscrita en español.
Caso de uso ideal:Empresas españolas y sectores legales o académicos para procesar contratos, informes financieros o tesis en español. Sincronización multidispositivo y exportación a múltiples formatos profesionales.
Punto adicional:Compatible con Windows y macOS. Funcionalidad integral, ideal para la digitalización de documentos a nivel profesional.
5. OCRmyPDF
Ventaja principal:Herramienta de línea de comandos compatible con Windows, macOS y Linux. Optimiza el reconocimiento del español utilizando el motor Tesseract. Añade texto OCR a PDF escaneados sin pérdida de calidad, generando PDF buscables. Admite procesamiento paralelo multinúcleo.
Caso de uso ideal:Para técnicos y empresas que procesan por lotes contratos o documentos oficiales en español. Incluye funciones auxiliares como corrección de inclinación y rotación de páginas. Optimiza y comprime el tamaño de los archivos procesados con alta eficiencia.
Punto adicional:Admite el reconocimiento de español antiguo y dialectos, ideal para escenarios especializados.
Cómo utilizan las empresas OCR
El objetivo central de la aplicación empresarial del OCR es "integrándolo en los flujos de trabajo para lograr una gestión de ciclo cerrado". No es necesario implementarlo todo a la vez; se puede elegir el método que mejor se adapte a la escala:
1. Pequeñas y Medianas Empresas
Utilizan herramientas listas para usar como PDF Agile, con cero desarrollo y bajo costo. Esto satisface necesidades como la digitalización de documentos dispersos o el procesamiento de reembolsos a pequeña escala, permitiendo una rápida adopción.
2. Empresas Medianas y Grandes
Integran la capacidad de OCR en sus sistemas existentes a través de API/SDK, optimizando la etapa de entrada de información sin alterar los flujos de trabajo establecidos. El período de implementación es de 1 a 4 semanas, con un costo controlable.
3. Grandes Empresas / Industrias con Información Confidencial
Colaboran con proveedores para personalizar modelos de reconocimiento y realizar una implementación privada. Esto satisface necesidades de procesamiento por lotes a gran escala, reconocimiento de formatos especiales y altos requisitos de privacidad.
Conclusión
ocr que es?Hoy en día, la tecnología OCR ha trascendido su función como una simple herramienta de reconocimiento de texto para convertirse en un puente clave que derriba la barrera entre el "texto en imágenes" y los "datos digitales". Se fundamenta en cuatro eslabones tecnológicos centrales y, gracias a su diversa clasificación, se adapta a las necesidades de innumerables industrias. No solo impulsa el desarrollo empresarial al reducir costos y mejorar la eficiencia, sino que también empodera a individuos y escenarios gubernamentales al simplificar operaciones y mejorar la experiencia. Además, en el mercado español, ha impulsado el desarrollo de herramientas de calidad como PDF Agile y ABBYY FineReader, adaptadas al idioma y las necesidades locales, permitiendo que esta "revolución de la lectura" impregne cada detalle de la vida y el trabajo.
Preguntas frecuentes
¿Qué es la capacitación en OCR?
El OCR training se refiere al proceso de mejorar la precisión con la que un sistema OCR extrae y reconoce texto de las imágenes, mediante la optimización de algoritmos y el aprendizaje a partir de datos. El objetivo central es que el modelo comprenda con precisión las características de los caracteres en diferentes escenarios, reduciendo los errores de reconocimiento.
¿Qué es OCR en IA?
El OCR en la IA es una tecnología central que combina la visión por computador y el procesamiento del lenguaje natural. Su función principal es convertir información textual en imágenes, ya sea impresa o manuscrita, en texto digital editable y buscable. Utilizando algoritmos de IA, simula la lógica del reconocimiento visual humano: primero preprocesa la imagen, luego localiza las áreas de texto, extrae las características de los caracteres y finalmente completa la correspondencia y traducción del texto.
¿Qué es OCR en capital humano?
El OCR en el capital humano se centra en convertir documentos relacionados con el personal (en papel o formato imagen) en texto digital, apoyando así la gestión eficiente de todo el ciclo del capital humano. A través de la tecnología OCR, la gestión del capital humano logra automatizar el almacenamiento de archivos, la recuperación de información y las estadísticas de datos. Esto libera a los profesionales de RRHH de las tareas repetitivas de entrada de datos, permitiéndoles concentrarse en funciones centrales como la contratación y formación de talento, al mismo tiempo que mejora la precisión y la trazabilidad en la gestión de los datos humanos, apoyando la toma de decisiones digitalizadas en este ámbito.