












Das Extrahieren von Text aus PDF-Dokumenten ist für verschiedene Zwecke wie Forschung, Datenanalyse und Content-Management unerlässlich geworden. Ein PDF-Text-Extraktionswerkzeug kann das Extrahieren und Verwenden von Textinformationen aus PDF-Dokumenten erheblich vereinfachen. Entdecken Sie die Bedeutung der Textextraktion aus PDFs, die Vorteile der OCR-Technologie (Optische Zeichenerkennung) und alternative Methoden für die Textextraktion ohne OCR.
Wir vereinfachen den Prozess, indem wir fünf effektive Methoden vorstellen, um Text aus jeder PDF mit OCR für bildbasierte Scans und ohne OCR für digitale Dokumente zu extrahieren. Diese Lösungen decken unterschiedliche Bedürfnisse und technische Fertigkeiten ab, von schnellem manuellem Kopieren bis hin zur Batch-Verarbeitung mehrerer Dokumente. Es gibt kein kompliziertes Fachjargon und keine unnötigen Schritte – nur klare und umsetzbare Techniken, die einfach funktionieren.
Am Ende wissen Sie genau, wie Sie diese Methoden anwenden können!
- Scannen Sie PDFs in bearbeitbaren Text um.
- Bewahren Sie die Formatierung beim Exportieren nach Word oder Excel.
- Extrahieren Sie Text aus mehreren Dateien gleichzeitig.
- Bearbeiten Sie gesperrte oder passwortgeschützte Dokumente.
- Wählen Sie das richtige Tool für Ihre spezifische Aufgabe.
Hören Sie auf, Text neu zu tippen, und beginnen Sie, effizient zu extrahieren. Lassen Sie uns anfangen.
Die Bedeutung der Textextraktion aus PDFs
Die Textextraktion aus PDF-Dokumenten ermöglicht einen einfacheren Zugriff auf die darin enthaltenen Informationen. Sie kann die Effizienz des Workflows erheblich verbessern, indem sie das Suchen nach spezifischen Schlüsselwörtern erleichtert, die Analyse des Inhalts vereinfacht oder den Text für andere Dokumente weiterverwendet. Nutzer können Zeit sparen und die Produktivität steigern, indem sie PDF-Text in ein Format konvertieren, das besser bearbeitbar und durchsuchbar ist.
OCR-Technologie ist ein leistungsstarkes Werkzeug zum Extrahieren von Text aus gescannten PDFs oder Bildern. Alternative Methoden können jedoch ebenfalls verwendet werden, um Text aus PDF-Dateien zu extrahieren, ohne darauf angewiesen zu sein. Sie können Ihr Toolkit zur Textextraktion erweitern und den geeignetsten Ansatz wählen, indem Sie diese zusätzlichen Techniken erkunden.
Verschiedene Methoden zur Textextraktion aus PDF mit und ohne OCR
Die Textextraktion aus PDFs ist eine häufige, jedoch frustrierende Herausforderung, wenn man mit gescannten Dokumenten, gesperrten Dateien oder schlecht formatierten Inhalten zu tun hat. Wenn Sie ein Student sind, der Forschung zusammenstellt, ein Profi, der Verträge bearbeitet, oder jemand, der versucht, ein PDF zu bearbeiten, kann die Unfähigkeit, Text zu kopieren, wertvolle Zeit und Energie verschwenden.
Die Arbeit mit PDFs erfordert häufig die Extraktion von Text zum Bearbeiten oder zur Wiederverwendung. Egal, ob Ihr Dokument durchsuchbaren Text oder gescannte Seiten enthält, hier sind 4 einfache Methoden, um die Aufgabe zu erledigen – mit und ohne OCR-Technologie.
Methode 1: Text mit der OCR-Funktion von PDF Agile extrahieren
OCR (Optische Zeichenerkennung) ist entscheidend für gescannte PDFs oder bildbasierte Dokumente. Die integrierte OCR-Technologie von PDF Agile konvertiert Textbilder präzise in bearbeitbaren und durchsuchbaren Inhalt und bewahrt dabei die Formatierung. Diese leistungsstarke Funktion spart Stunden manuelles Abtippen und funktioniert bemerkenswert gut, selbst bei niedrigauflösenden Scans.
Schritte:
1. Öffnen Sie PDF Agile und laden Sie Ihre gescannte PDF-Datei.

2. Klicken Sie auf die Schaltfläche „OCR“ in der Symbolleiste.

3. Der Text Ihres Dokuments wurde nun extrahiert.
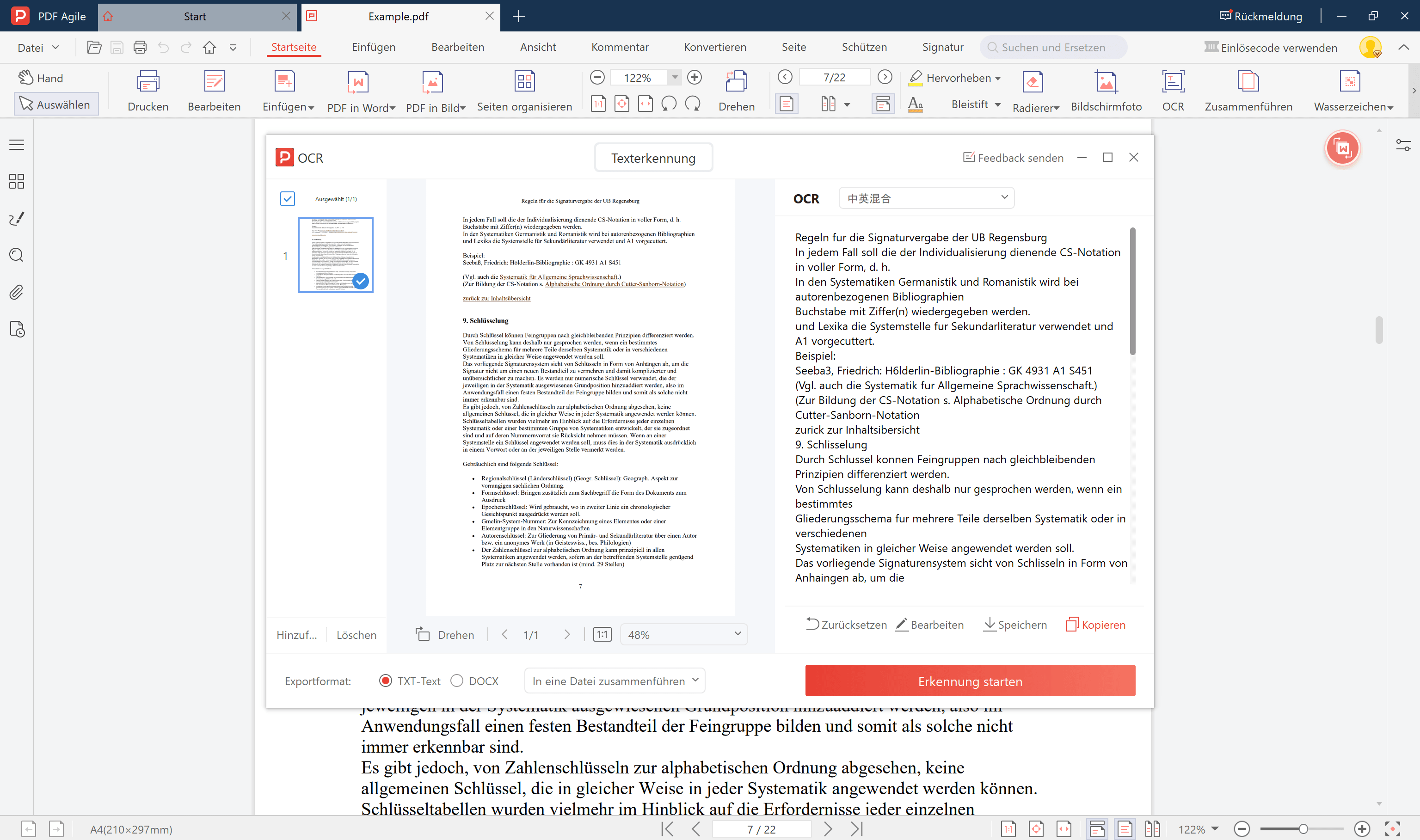
4. Wählen Sie zwischen TXT-Text oder Docx-Ausgabeformat.
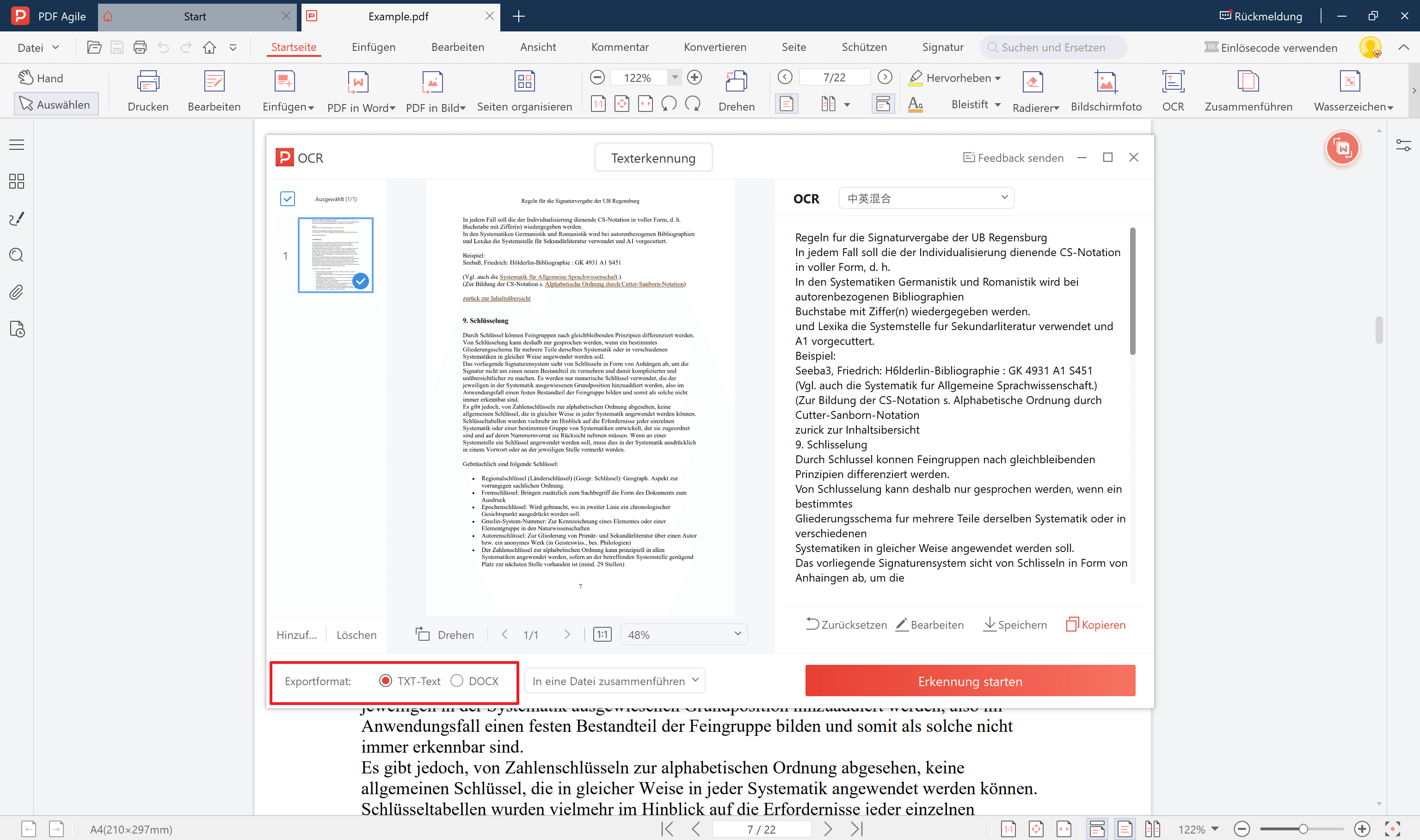
5. Sie können den Text nun bearbeiten oder speichern.
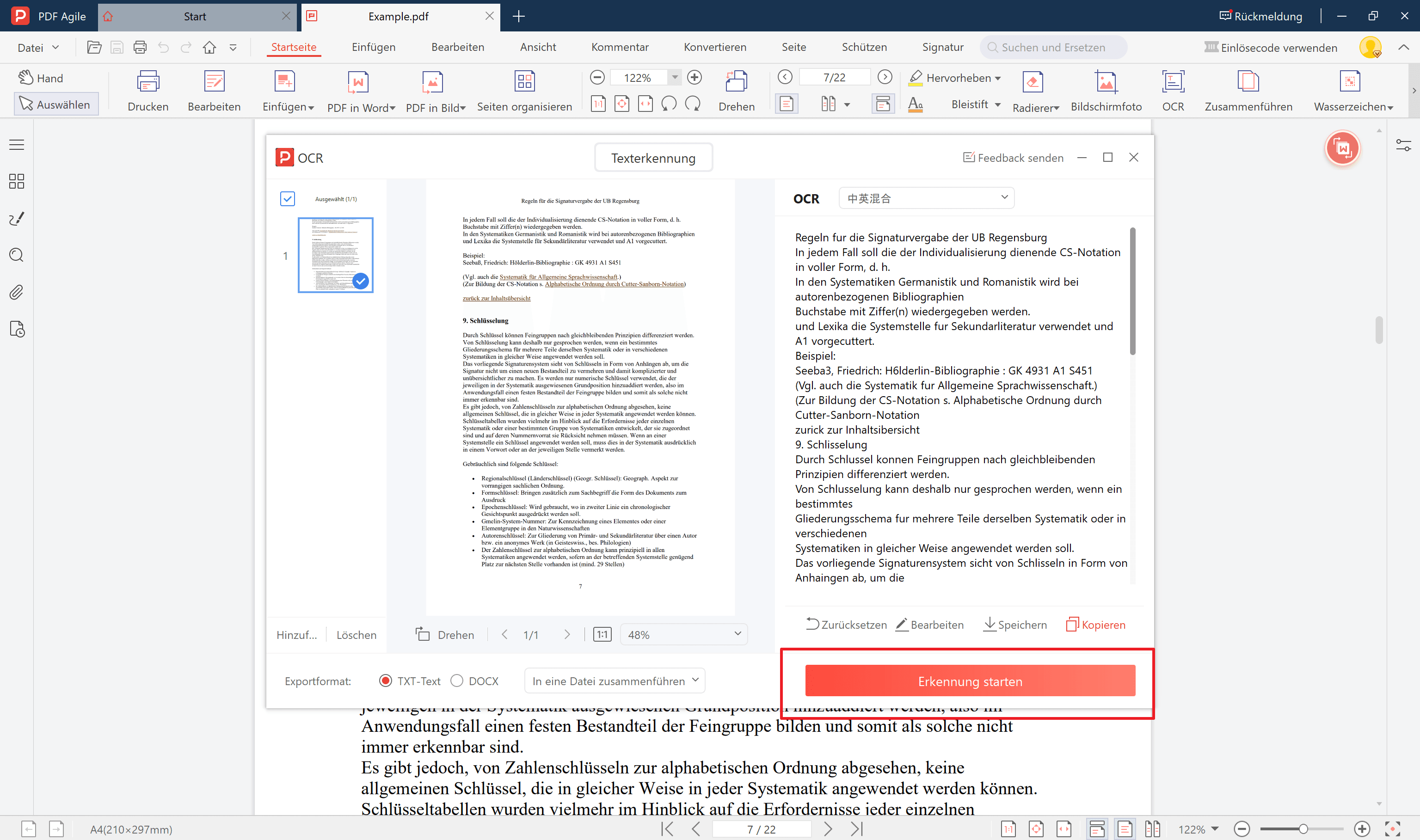
6. Der Text ist nun auswählbar – kopieren Sie, was Sie benötigen!
Methode 2: Text mit der Exportfunktion von PDF Agile extrahieren
Die Exportfunktion von PDF Agile bietet den einfachsten Weg, um Text aus standardmäßigen, textbasierten PDFs zu extrahieren. Im Gegensatz zu OCR, das Bilder verarbeitet, konvertiert diese Methode sofort lesbaren PDF-Text in bearbeitbare Formate, während sie die Absatzerstellung und grundlegende Formatierungen beibehält.
Schritte:
1. Öffnen Sie die PDF Agile-Oberfläche und gehen Sie zum Dateibereich oben links.
2. Klicken Sie auf das Export-Symbol und wählen Sie Ihr Ausgabeformat, um Text zu extrahieren.
3. Ein Pop-up-Fenster erscheint zur Konvertierung des Textes in das gewünschte Format.
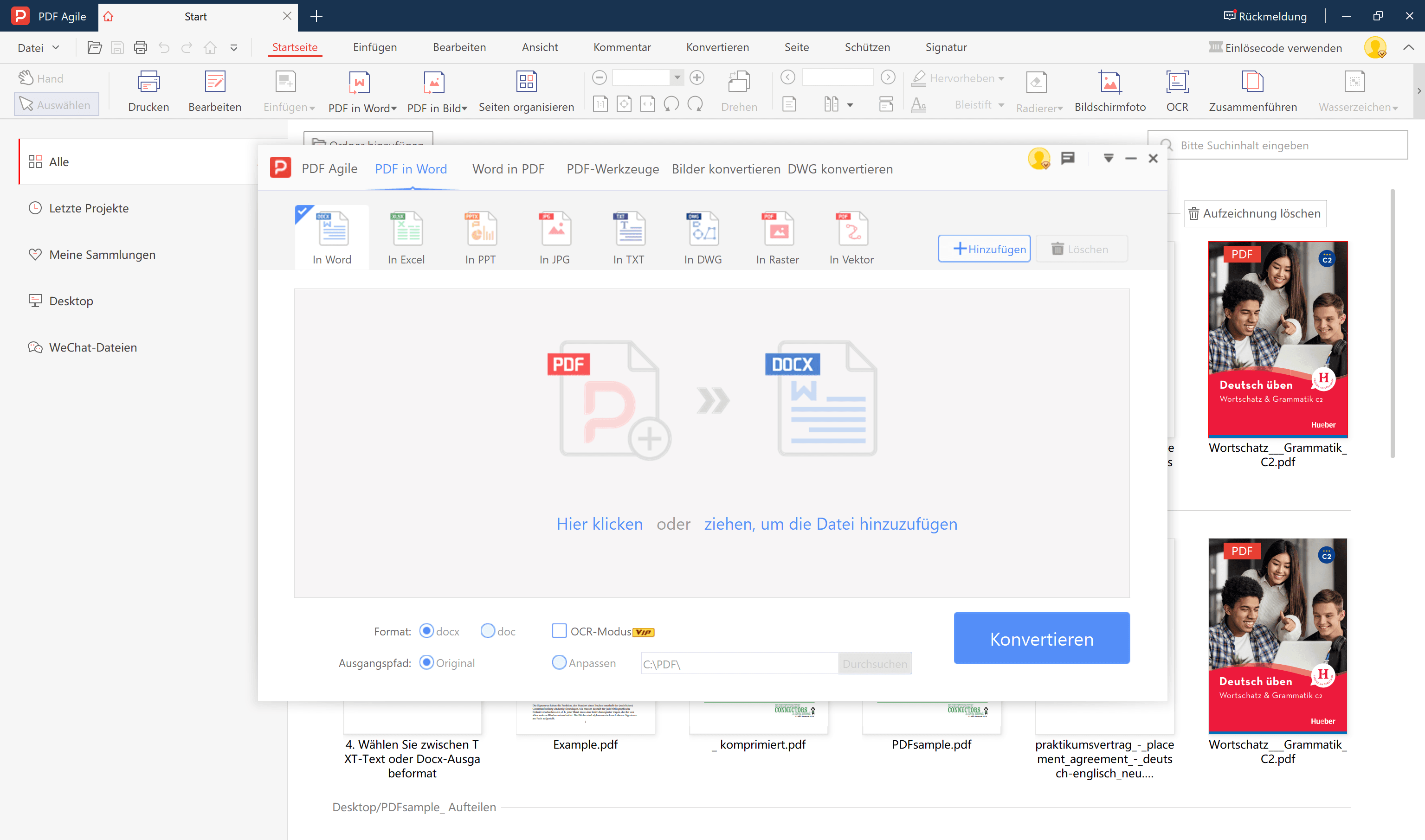
4. Wählen Sie den Abschnitt „Hinzufügen“ und laden Sie Ihr PDF-Dokument hoch.
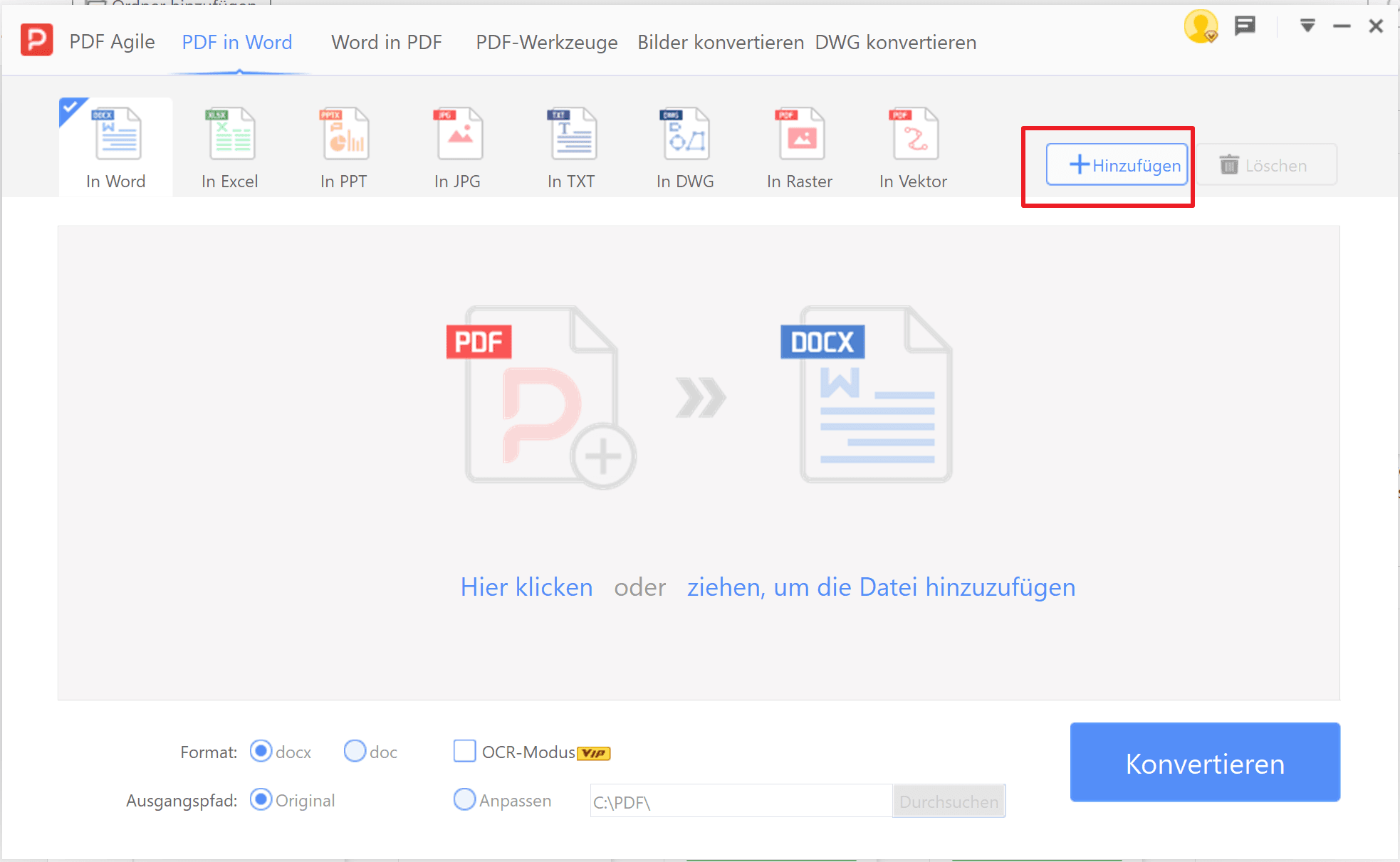
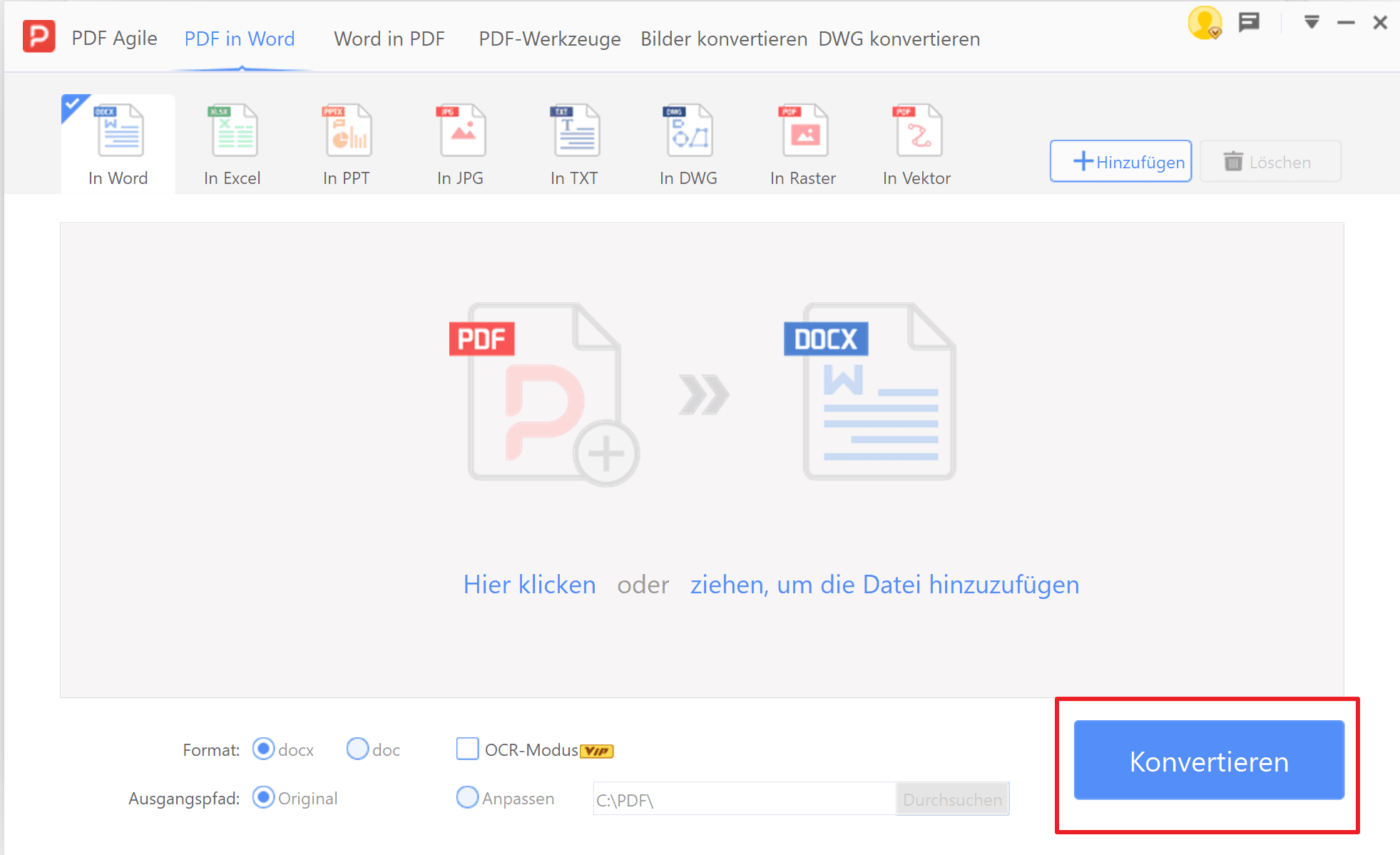
5. Klicken Sie auf „Konvertieren“ und warten Sie ein paar Sekunden auf die Umwandlung.
6. Ihre Datei ist nun bereit, um Text zu extrahieren. Öffnen Sie Ihre Datei im PDF Agile-Editor und beginnen Sie mit der Extraktion.
Methode 3: Manuelle Textextraktion im Bearbeitungsmodus
Der direkte Bearbeitungsmodus von PDF Agile bietet präzise Kontrolle für schnelle, selektive Textextraktionen aus standardmäßigen PDFs. Diese Methode ist besonders nützlich, wenn Sie nur Teile des Textes benötigen, anstatt das gesamte Dokument, und bietet den zusätzlichen Vorteil einer Echtzeit-Formatierungsanzeige. Die Benutzeroberfläche ähnelt gängigen Textverarbeitungsprogrammen und ist intuitiv zu bedienen.
Schritte:
1. Öffnen Sie die PDF-Datei in PDF Agile und klicken Sie auf den „Bearbeiten“-Modus.
2. Klicken Sie mit der rechten Maustaste auf den gewünschten Text und wählen Sie „Kopieren“ oder drücken Sie „Strg+C“.

3. Fügen Sie den Text in eine beliebige externe Anwendung ein.
4. Verwenden Sie die Formatierungs-Symbolleiste, um Schriftart/Größe bei Bedarf anzupassen.
Methode 4: Text aus PDF-Bildern in Adobe Acrobat extrahieren
Die fortschrittliche OCR-Engine von Adobe Acrobat verarbeitet komplexe Dokumentenlayouts und Scans mit niedriger Auflösung mit außergewöhnlicher Präzision. Die KI-unterstützte Texterkennung unterstützt mehr als 100 Sprachen und bewahrt Tabellen, Spalten und komplexe Formatierungen besser als viele Alternativen. Beachten Sie jedoch, dass ein kostenpflichtiges Abonnement erforderlich ist.
Schritte:
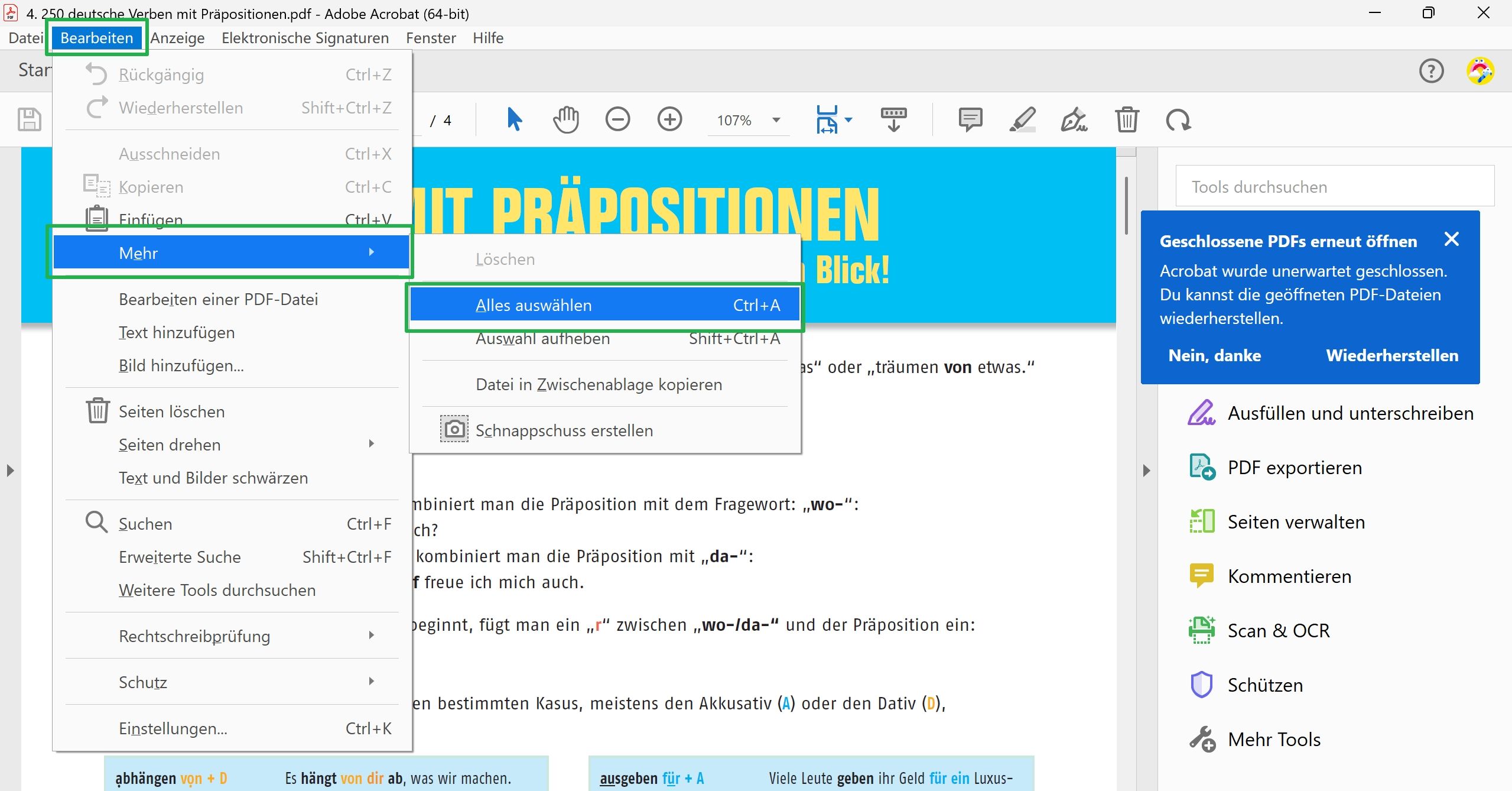
1. Öffnen Sie die PDF in Adobe Acrobat (nicht Reader).
2. Navigieren Sie zu „Bearbeiten“ und klicken Sie auf „Alles auswählen“.
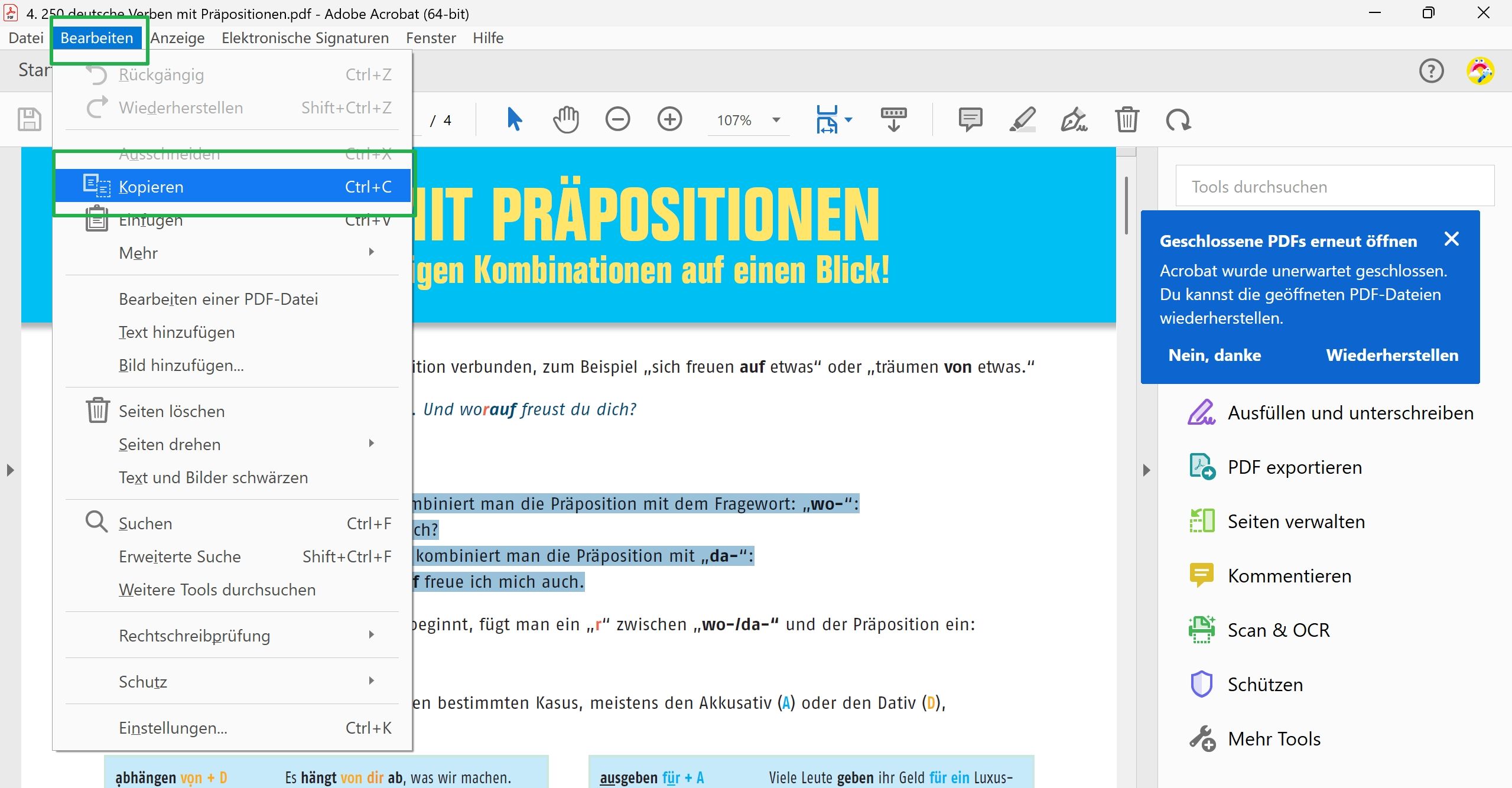
3. Ziehen Sie den Cursor über den Text, um ihn zu kopieren. Sie können auch mit der rechten Maustaste klicken, um den Text zu kopieren.
Erweiterte Tipps für die Textextraktion
- Reguläre Ausdrücke (Regex): Verwenden Sie reguläre Ausdrücke (Regex), um nach spezifischen Mustern oder Formaten innerhalb des extrahierten Textes zu suchen. Diese fortgeschrittene Technik kann Ihnen helfen, Text genauer und effizienter zu extrahieren, indem Sie benutzerdefinierte Suchstandards definieren.
- Batch-Verarbeitung: Erwägen Sie die Verwendung von Batch-Verarbeitungstools, um den Extraktionsprozess zu automatisieren, wenn Sie viele PDF-Dateien haben, aus denen Text extrahiert werden muss. Dies spart Ihnen Zeit und Mühe bei der gleichzeitigen Verarbeitung mehrerer Dateien.
- Metadatenextraktion: Versuchen Sie, die Textinhalte sowie die Metadateninformationen aus den PDF-Dokumenten zu extrahieren. Diese zusätzlichen Daten können Aufschluss über den Autor des Dokuments, das Erstellungsdatum und mehr geben und das Gesamtverständnis des Inhalts verbessern.
- Integration mit Dokumentenmanagementsystemen: Integrieren Sie Ihr Textextraktionswerkzeug in Dokumentenmanagementsysteme oder Cloud-Speicherdienste, um die extrahierte Version zu speichern. Dies kann die Zugänglichkeit und Organisation der extrahierten Textstatistiken verbessern.
Diese fortgeschrittenen Tipps für Ihren Textextraktions-Workflow ermöglichen es Ihnen, den Extraktionsprozess zu optimieren und die Genauigkeit zu verbessern. Sie helfen auch dabei, extrahierten Text aus PDF-Dateien effizient zu verwalten.
Häufig gestellte Fragen (FAQs)
Wie kann ich Text aus einer gescannten PDF extrahieren?
Sie können OCR-Tools wie PDF Agile verwenden, um gescannte Bilder in bearbeitbaren Text zu konvertieren.
Warum lässt mich meine PDF keinen Text kopieren?
- Es könnte sich um eine gescannte/bildbasierte PDF handeln (verwenden Sie OCR).
Die Datei könnte passwortgeschützt sein (entsperren Sie sie zuerst mit der entsprechenden Berechtigung).
Der Text ist möglicherweise nicht auswählbar (versuchen Sie manuelle Extraktion oder OCR).
Wie extrahiere ich Text aus mehreren PDFs gleichzeitig?
Verwenden Sie die Batch-Verarbeitung in PDF Agile:
- Öffnen Sie das Batch-Tool.
- Fügen Sie Ihre PDFs hinzu.
- Wählen Sie „Text extrahieren“.
- Wählen Sie einen Ausgabefolder.
Gibt es eine Möglichkeit, Text aus einer PDF ohne Software zu kopieren?
Ja! Für digitale PDFs (keine Scans):
- Öffnen Sie sie in Google Drive (Rechtsklick, dann „Mit Google Docs öffnen“).
- Oder verwenden Sie „Strg+C“ (wenn der Text auswählbar ist).
Wie extrahiere ich Text aus einer passwortgeschützten PDF?
Wenn Sie das Passwort haben:
- Öffnen Sie die PDF mit einem Tool wie PDF Agile.
- Geben Sie das Passwort ein, wenn Sie dazu aufgefordert werden.
- Exportieren oder kopieren Sie den Text.
Hinweis: Umgehen Sie Passwörter niemals ohne Erlaubnis.
Warum sieht mein extrahierter Text chaotisch aus?
Bei gescannten PDFs können OCR-Fehler auftreten (versuchen Sie, die Scanqualität zuerst zu verbessern).
Bei digitalen PDFs kann komplexe Formatierung (Tabellen, Spalten) nicht ordentlich kopiert werden. Verwenden Sie „Exportieren nach Word“ für bessere Ergebnisse.
Fazit
Die Textextraktion aus PDFs, sei es aus gescannten Bildern oder digitalen Dateien, muss nicht kompliziert sein. Die richtigen Werkzeuge und Techniken können selbst die hartnäckigsten PDFs schnell in bearbeitbaren, wiederverwendbaren Text umwandeln.
- Für gescannte PDFs: OCR-Tools wie PDF Agile verwandeln Bilder zuverlässig in auswählbare Daten.
- Für digitale PDFs: Eingebaute Exportfunktionen oder einfache Kopieren-und-Einfügen-Methoden sparen Zeit ohne zusätzliche Software.
- Für Bulk-Extraktion: Batch-Verarbeitung hilft, mehrere Dateien gleichzeitig zu verarbeiten, was ideal für große Projekte ist.
- Für gesperrte Dateien: Passwortschutz muss kein Hindernis sein – es gibt Umgehungsmöglichkeiten (mit entsprechender Berechtigung).
Wählen Sie immer die Methode, die zu Ihrem Dokumenttyp und Ihren Bedürfnissen passt. Manuelles Kopieren funktioniert, wenn Sie nur einen Absatz benötigen. Automatisiertes OCR ist Ihr bester Freund für Archive gescannter Seiten.
Nun, da Sie diese Tricks kennen, verabschieden Sie sich vom Neutippen und begrüßen Sie die nahtlose Textextraktion. Viel Spaß beim Bearbeiten!



