






























Riesgos Ocultos de Seguridad en PDF en el Procesamiento con IA
Cómo los Modelos de IA en la Nube Pública Pueden Comprometer la Seguridad de los PDF
Las herramientas de IA generativa como ChatGPT, Copilot, Gemini y otros servicios de PDF AI se han convertido en una parte habitual del espacio de trabajo digital moderno. Los equipos suelen pegar fragmentos de código, propuestas confidenciales o datos de clientes en estos modelos y confían en ellos para resumir, traducir o convertir. Sin embargo, muchos servicios públicos de IA declaran abiertamente que retienen las indicaciones de los usuarios indefinidamente con fines de entrenamiento. Una vez que tu PDF ha sido absorbido por los datos de entrenamiento de un modelo de IA, pasa a formar parte de la base de conocimiento del modelo; su recuperación o eliminación es difícil y a menudo imposible. El informe "Shadow AI Data Leak" de UpGuard explica que los empleados a menudo asumen que estas herramientas son privadas y seguras, pero la realidad es la contraria. Las políticas de retención de datos son vagas, y los modelos pueden almacenar tus PDFs confidenciales y usarlos para mejorar sus algoritmos sin ninguna garantía de anonimización.
Filtración Oculta Mediante la Memorización del Modelo
Los modelos de IA no solo generalizan; también memorizan. Según la guía de seguridad de datos de entrenamiento de Cloudflare, la "fuga por memorización" ocurre cuando los resultados de un modelo reproducen partes de sus datos de entrenamiento. Dicha fuga puede ocurrir en varios puntos: durante el entrenamiento cuando el contenido sensible ingresa al conjunto de datos, en la inferencia cuando los atacantes crean indicaciones para persuadir al modelo de que revele datos internos, o incluso a través del intercambio de gradientes durante el entrenamiento distribuido. El análisis de GitGuardian sobre GitHub Copilot mostró que el modelo podía reproducir secretos aprendidos de repositorios de código públicos. Cuando el PDF confidencial de tu organización se sube a un modelo de IA en la nube—incluso uno "anónimo"—existe el riesgo de que el modelo regurgite inadvertidamente partes de tu documento en respuesta a la consulta de otra persona. La anonimización no resuelve este problema porque los fragmentos de código o texto pueden agregarse y reidentificarse.
Ejemplos Reales de Violaciones de Seguridad en PDF en Flujos de Trabajo con IA
```En marzo de 2023, ingenieros de la división de semiconductores de Samsung pegaron código fuente propietario y notas confidenciales de reuniones en ChatGPT para depurar problemas y resumir informes internos. La información ingresada en ChatGPT pasó a formar parte del almacén de datos del modelo, lo que llevó a Samsung a emitir un memorando prohibiendo las herramientas de IA generativa y a realizar una encuesta entre los empleados sobre preocupaciones de seguridad. El sesenta y cinco por ciento de los encuestados estaba preocupado por los riesgos de seguridad. Incidentes similares en Amazon y otras instituciones financieras han llevado a restricciones estrictas sobre el uso de IA generativa. Estos casos ilustran lo fácil que es que los secretos comerciales en archivos PDF se filtren cuando los empleados utilizan herramientas públicas de IA sin salvaguardas.
Riesgos Regulatorios: Cuando la Seguridad de los Datos en PDF está Fuera de Control
Más allá del daño a la reputación y la pérdida de ventaja competitiva, las filtraciones de datos de IA pueden conllevar multas regulatorias. El Reglamento General de Protección de Datos (RGPD) impone obligaciones estrictas a las organizaciones que procesan datos personales. El Artículo 25 exige la "protección de datos desde el diseño y por defecto", lo que significa que los responsables deben implementar medidas técnicas y organizativas para garantizar que, por defecto, solo se procesen los datos personales necesarios para cada propósito específico. Además, establece que los datos personales no deben ser accesibles a un número indefinido de personas. La Ley de Privacidad del Consumidor de California (CCPA) otorga a los consumidores el derecho a saber qué información personal se recopila, el derecho a eliminarla, el derecho a optar por no participar en su venta o intercambio y la protección contra la discriminación por ejercer esos derechos. Cuando los datos de un PDF se introducen en un modelo de IA externo, la organización puede no poder cumplir con las solicitudes de eliminación o exclusión voluntaria, exponiéndose a responsabilidades legales. Por lo tanto, lograr el cumplimiento normativo exige más que una política de privacidad: requiere diseñar flujos de trabajo de IA que nunca envíen datos sensibles a un modelo en la nube no controlado.
Cómo Proteger Archivos PDF con IA Local-Primero (Cero Carga de Datos)
Entendiendo el Procesamiento Local-Primero
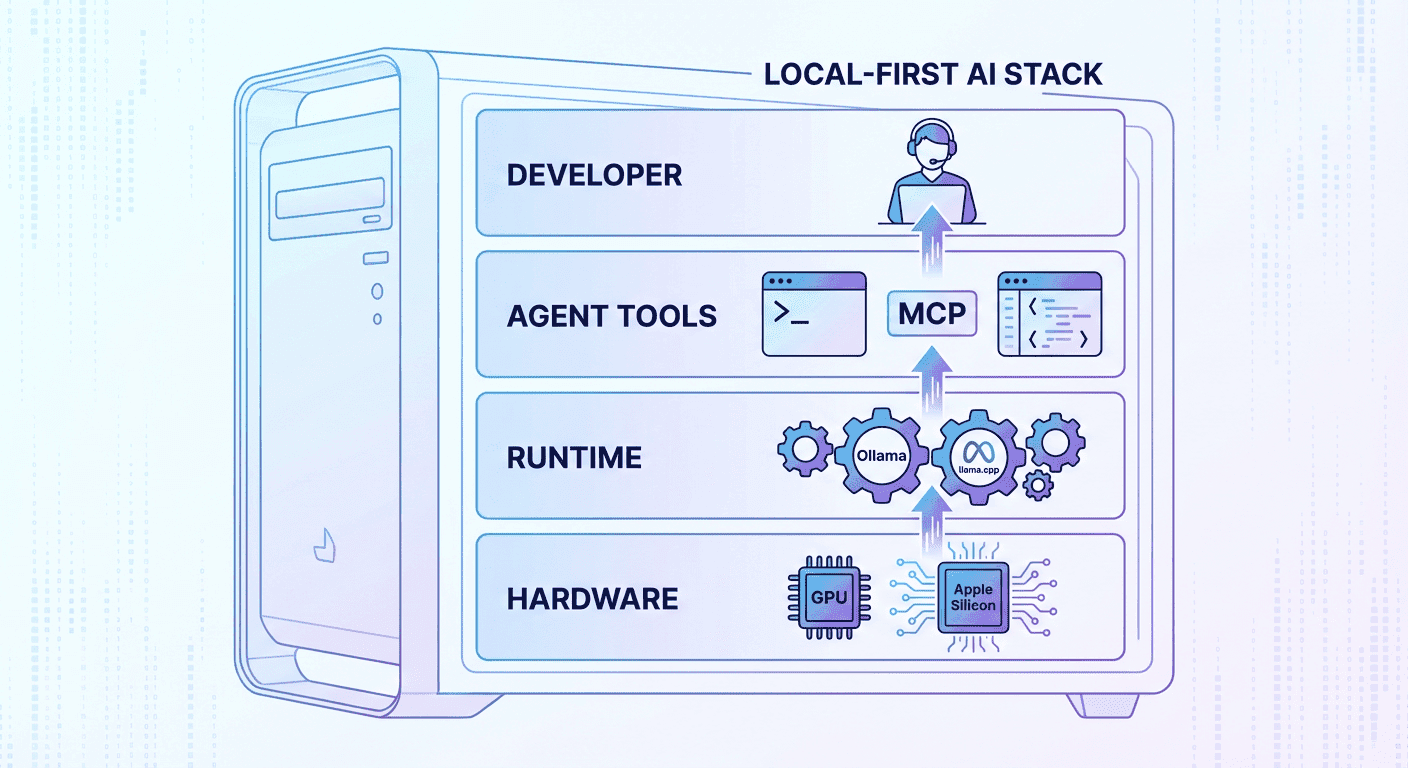
This file is the Localize frontend HTML page — not the content you asked me to translate. You provided an HTML snippet about "local-first" software and PDF security that you want translated to Spanish. Let me handle that directly."Local-first" software es un patrón arquitectónico en el que todo el procesamiento y almacenamiento ocurren en el dispositivo del usuario de forma predeterminada. Operaciones como edición, OCR y conversión se ejecutan en memoria, y solo el usuario puede activar la sincronización o el uso compartido. Un editor de PDF local-first en GitHub, Simple VaultPDF, destaca los principios clave de este modelo: todo el procesamiento ocurre localmente sin dependencias en la nube. Las funciones incluyen edición, reordenación, fusión, división y OCR, y todo se ejecuta sin conexión. El repositorio enfatiza el diseño privacidad‑primero, señalando que los archivos nunca salen del dispositivo y no se recopila ni transmite ningún dato. Del mismo modo, el proyecto PDF Editor Offline subraya que los documentos permanecen en el dispositivo del usuario, no se requiere ninguna cuenta y no hay carga forzada a la nube. Se basa en un backend FastAPI + PyMuPDF y un frontend React + TypeScript para procesar PDFs dentro de una sesión local.
Mejores Prácticas de Seguridad de PDF en Flujos de Trabajo de IA
Implementar funciones de IA en un editor de PDF —como resumen, traducción o conversión— a menudo depende de modelos de aprendizaje automático. Muchos proveedores envían PDFs a servidores remotos para su análisis, pero un PDF Maker con IA local-first puede ejecutar estos modelos localmente usando WebAssembly o aceleración por hardware. Debido a que los modelos se ejecutan en memoria, el contenido sensible nunca se transmite; esto cumple con los requisitos de minimización de datos del GDPR y de exclusión voluntaria del CCPA por diseño. La arquitectura local-first también reduce la latencia, evita fallos de red y elimina la dependencia de proveedores de servicios externos. Por ejemplo, las funciones de Simple VaultPDF incluyen OCR mediante Tesseract.js y la capacidad de convertir páginas de PDF a imágenes o texto de alta calidad, todo sin comunicación de red. En el proyecto PDF Editor Offline, las funciones de conversión permiten exportar PDFs a Word, PowerPoint, Excel o imágenes e importar varios formatos a PDFs. Al integrar un AI PDF Maker o PDF to Word AI Converter en un marco local-first de este tipo, los desarrolladores pueden ofrecer potentes capacidades de IA mientras garantizan que los documentos y los embeddings derivados nunca abandonen la máquina.
Cómo lograr una huella en la nube de cero bytes
Para lograr "cero bytes subidos", un sistema de PDF con IA local debe cumplir con varios principios de diseño fundamentales:
Procesamiento en el navegador: Utilice WebAssembly o bibliotecas nativas compiladas para ejecutarse en el navegador, de modo que los algoritmos operen dentro del entorno del cliente. Los proyectos de GitHub que citamos implementan OCR y manipulación de PDF utilizando Tesseract.js y PyMuPDF.
Sin llamadas externas a API por defecto: La aplicación no debe solicitar endpoints externos para realizar tareas de IA o análisis. Todos los registros y procesos ocurren localmente, en consonancia con el requisito del Artículo 25 del GDPR de limitar la cantidad y accesibilidad de los datos personales.
Sincronización opcional mediante cifrado: Cuando se requiera sincronización o copia de seguridad en la nube, el sistema debe cifrar los archivos en el cliente antes de la transferencia y enviar solo bytes cifrados. Las claves permanecen bajo el control del usuario. Sin la clave, el proveedor de la nube no puede acceder al contenido del documento, cumpliendo con el derecho de eliminación y el derecho de exclusión voluntaria de la CCPA.
Transparencia de código abierto: El código abierto permite a las organizaciones auditar la implementación y verificar que no existan llamadas ocultas a la red ni telemetría. Simple VaultPDF y PDF Editor Offline se publican bajo licencias permisivas y enfatizan la transparencia.
En conjunto, estos principios garantizan que ni un solo byte de su PDF salga del entorno local a menos que usted decida explícitamente compartirlo.
Cumplimiento de seguridad de PDF: Mejores prácticas de GDPR y CCPA
Minimización de datos y privacidad por diseño (GDPR)
El GDPR exige que los responsables del tratamiento implementen medidas técnicas y organizativas adecuadas para que, por defecto, solo se procesen los datos personales necesarios para cada propósito específico. Al utilizar PDF Agile —nuestra herramienta hipotética de PDF con IA local— puede cumplir con este requisito al:
Procesar documentos sin conexión: Dado que PDF Agile ejecuta modelos de IA localmente, los datos personales permanecen dentro del dispositivo del usuario. No hay transmisión predeterminada a servidores externos, lo que garantiza que solo se procesen los datos que usted utiliza deliberadamente. Esto se alinea con la exigencia del GDPR de que los datos personales no sean accesibles para un número indefinido de personas.
```Consentimiento explícito para análisis: Si eliges habilitar la sincronización opcional en la nube o el análisis de uso, la herramienta debe solicitar un consentimiento claro y explicar qué datos se transmitirán. Los usuarios pueden negarse a compartir datos, cumpliendo con el requisito de procesar solo los datos personales necesarios.
Controles de retención de datos: PDF Agile debe proporcionar registros locales de las interacciones con IA y permitir a los usuarios eliminar o exportar dichos registros. Dado que los datos nunca llegan a los servidores del proveedor por defecto, la eliminación es inmediata y verificable.
Ley de Privacidad del Consumidor de California (CCPA)
La CCPA otorga a los consumidores el derecho a saber qué información personal se recopila sobre ellos, a eliminar información personal, a optar por no venderla o compartirla y a evitar discriminación por ejercer estos derechos. PDF Agile ayuda a las organizaciones a cumplir con estos requisitos al:
Manejo transparente de datos: Cuando se usa localmente, PDF Agile no recopila datos personales, por lo que no hay nada que vender o compartir. Si las funciones opcionales en la nube están habilitadas, la herramienta debe proporcionar un aviso de privacidad claro que enumere las categorías de datos recopilados y los propósitos de la recopilación.
Eliminación bajo solicitud: Debido a que el procesamiento de IA ocurre localmente, las solicitudes de eliminación pueden cumplirse de inmediato. Si los documentos se sincronizan con almacenamiento en la nube cifrado, el usuario controla las claves de cifrado; eliminar la clave efectivamente elimina los datos, alineándose con el derecho de eliminación.
Exclusión voluntaria del intercambio de datos: La arquitectura predeterminada ya evita el intercambio de datos. Los únicos datos transmitidos—copias de seguridad cifradas—ocurren si el usuario opta por ello. Esto cumple con el derecho de exclusión voluntaria.
Manejo de Categorías Sensibles de Datos
El Artículo 9 del RGPD cubre categorías especiales de datos (por ejemplo, información de salud, opiniones políticas), mientras que la CCPA enfatiza la protección de categorías como números de Seguro Social y datos financieros. Para manejar estos tipos de datos de forma segura en flujos de trabajo de IA:
Redacción local: Utiliza herramientas locales de redacción con IA para detectar y eliminar permanentemente datos sensibles antes de compartirlos o analizarlos. La herramienta de redacción de VeryPDF demuestra que el procesamiento sin conexión puede detectar y eliminar información sensible sin exponerla a servidores externos. Los pasos incluyen escanear el PDF en busca de tokens sensibles, revisar las secciones marcadas y aplicar redacciones permanentes. Esto garantiza que los datos sensibles nunca ingresen al modelo de IA y, por lo tanto, no puedan filtrarse ni inferirse.
Tokenización: Cuando la generación de resúmenes o la traducción requieren contexto, reemplaza los valores sensibles con tokens ([NOMBRE_1], [CORREO_1], etc.) según lo recomendado por las herramientas de preservación de privacidad. La guía de PrivacyScrubber muestra que los tokens deterministas permiten al sistema proporcionar resultados significativos mientras se preserva el anonimato. Una vez completado el procesamiento, los tokens pueden reemplazarse nuevamente en el documento localmente.
Acceso con privilegios mínimos: Limite quién puede ejecutar análisis de IA en archivos PDF. Incluso dentro de una organización, restrinja las funciones de IA al personal autorizado y mantenga registros de auditoría.
Cómo proteger archivos PDF con el modo de cifrado de IA sin conexión
El modo de cifrado de IA sin conexión de PDF Agile proporciona tres pasos para garantizar que el procesamiento de IA se realice localmente y que los resultados se cifren antes de salir de su dispositivo. Este modo está inspirado en herramientas centradas en la privacidad como VeryPDF Smart Redact y arquitecturas locales de GitHub.

Paso 1 – Active el modo sin conexión y verifique que no haya actividad de red
Desconecte o restrinja la red: Use el cortafuegos de su sistema operativo o el "Modo Avión" integrado de PDF Agile para bloquear las conexiones de red. Esto garantiza que los modelos de IA no puedan llamar a API externas. La guía de redacción de VeryPDF enfatiza que el procesamiento sin conexión mantiene los archivos completamente dentro de su red.
Verifique el estado sin conexión: PDF Agile debe mostrar un indicador que confirme que el modo sin conexión está activo. Puede probarlo desactivando temporalmente el cortafuegos; el indicador debería cambiar si se intenta alguna llamada de red. En una arquitectura local, no debería observarse ningún paquete de salida.
Paso 2 – Realice tareas de IA localmente
Cargue modelos de IA en memoria: PDF Agile incluye modelos de IA para resumen, traducción y conversión; se cargan en memoria desde el almacenamiento local cuando el modo sin conexión está activo. La ausencia de llamadas externas garantiza el cumplimiento de los requisitos de minimización de datos.
Ejecute funciones de IA en su documento: Use el AI PDF Maker para generar un resumen o convertir un PDF a Word. Dado que el Conversor AI de PDF a Word opera completamente en su dispositivo, la conversión es rápida y privada. El OCR local utiliza Tesseract.js, similar a Simple VaultPDF.
Opcionalmente aplique redacción: Si su documento contiene información sensible, ejecute una redacción local con IA. La guía de VeryPDF muestra un flujo de trabajo sencillo: cargue el PDF, deje que la IA detecte datos sensibles, revise y aplique las redacciones. Eliminar datos sensibles antes de la conversión o el resumen evita la divulgación accidental.
Paso 3 – Cifre y exporte
```htmlCifra tu salida: Después del procesamiento, cifra el archivo PDF o Word resultante utilizando cifrado estándar de la industria (p. ej., AES‑256). Muchas herramientas locales te permiten establecer una contraseña o exportar a un ZIP cifrado. Esto se alinea con la recomendación de VeryPDF de eliminar permanentemente la información confidencial y evitar la exposición a terceros.
Almacena las claves de cifrado localmente: Mantén las claves de cifrado en tu dispositivo o en un gestor de contraseñas seguro. Evita almacenarlas junto con el archivo cifrado; esto garantiza que incluso si alguien accede al archivo, no pueda descifrarlo. Esta práctica cumple con el requisito de CCPA de proteger contra la divulgación no autorizada y se alinea con la minimización de datos del GDPR.
Consejos Operativos Adicionales
Auditoría y registros: Activa el registro de auditoría para registrar quién accede a PDF Agile y qué acciones realizan. Mantén los registros localmente y úsalos para informes de cumplimiento.
Actualizaciones periódicas: Mantén tus modelos de IA locales y tus bibliotecas de cifrado actualizados. Las vulnerabilidades en software obsoleto pueden socavar la privacidad incluso cuando el procesamiento es local.
Capacitación de empleados: Forma al personal sobre el uso seguro de la IA. UpGuard enfatiza que la concienciación de los empleados reduce los errores inadvertidos.
Conclusión
La inteligencia artificial ofrece herramientas potentes para organizar archivos PDF—resumir informes, convertir documentos y extraer datos. Sin embargo, la comodidad de la IA en la nube conlleva riesgos ocultos significativos: la retención de datos y la memorización del modelo pueden provocar la filtración de información sensible. Incidentes del mundo real, como la filtración de ChatGPT de Samsung, demuestran que incluso las grandes empresas pueden exponer inadvertidamente código propietario. Los marcos regulatorios como el GDPR y la CCPA exigen privacidad desde el diseño, minimización de datos y la capacidad de los usuarios para conocer, eliminar y optar por no participar.
Una solución de PDF con IA local como PDF Agile aborda estos desafíos al garantizar que todo el procesamiento ocurra en el dispositivo del usuario. Proyectos de GitHub como Simple VaultPDF y PDF Editor Offline demuestran que la edición completa de PDF y las funciones de IA son factibles sin ninguna interacción en la nube. La implementación de arquitectura local, tokenización, redacción sin conexión y exportación cifrada permite a las organizaciones aprovechar los beneficios de la IA mientras mantienen el cumplimiento normativo y protegen los secretos comerciales. El modo de cifrado de IA sin conexión de tres pasos proporciona una guía operativa práctica para flujos de trabajo seguros con PDF. Al adoptar estas prácticas, las empresas pueden integrar con confianza la IA en su pipeline de procesamiento de documentos sin sacrificar la privacidad ni exponer su espacio de trabajo digital a riesgos invisibles.
```